 | Chapter 3: User Accounts |  |

Now that we've had a good look at user identity, we can begin to address the administration aspect of user accounts. Rather than just show you the select Perl subroutines or function calls you need for user addition and deletion, we're going to take this topic to the next level by showing these operations in a larger context. In the remainder of this chapter, we're going to work towards writing a bare-bones account system that starts to really manage both NT and Unix users.
Our account system will be constructed in four parts: user interface, data storage, process scripts (Microsoft would call them the "business logic"), and low-level library routines. From a process perspective they work together (see Figure 3-2).
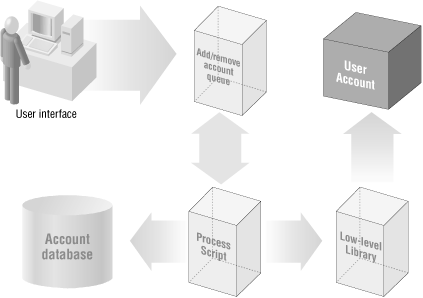
Requests come into the system through a user interface and get placed into an "add account queue" file for processing. We'll just call this an "add queue" from here on in. A process script reads this queue, performs the required account creations, and stores information about the created accounts in a separate database. That takes care of adding the users to our system.
For removing a user, the process is similar. A user interface is used to create a "remove queue." A second process script reads this queue and deletes the users from our system and updates the central database.
We isolate these operations into separate conceptual parts because it gives us the maximum possible flexibility should we decide to change things later. For instance, if some day we decide to change our database backend, we only need to modify the low-level library routines. Similarly, if we want our user addition process to include additional steps (perhaps cross-checking against another database in Human Resources), we will only need to change the process script in question.Let's start by looking at the first component: the user interface used to create the initial account queue. For the bare-bones purposes of this book, we'll use a simple text-based user interface to query for account parameters:
sub CollectInformation{
# list of fields init'd here for demo purposes, this should
# really be kept in a central configuration file
my @fields = qw{login fullname id type password};
my %record;
foreach my $field (@fields){
print "Please enter $field: ";
chomp($record{$field} = <STDIN>);
}
$record{status}="to_be_created";
return \%record;
}
This routine creates a list and populates it with the different fields of an account record. As the comment mentions, this list is in-lined in the code here only for brevity's sake. Good software design suggests the field name list really should be read from an additional configuration file.
Once the list has been created, the routine iterates through it and requests the value for each field. Each value is then stored back into the record hash. At the end of the question and answer session, a reference to this hash is returned for further processing. Our next step will be to write the information to the add queue. Before we see this code, we should talk about data storage and data formats for our account system.
The center of any account system is a database. Some administrators use their /etc/passwd file or SAM database as the only record of the users on their system, but this practice is often shortsighted. In addition to the pieces of user identity we've discussed, a separate database can be used to store metadata about each account, like its creation and expiration date, account sponsor (if it is a guest account), user's phone numbers, etc. Once a database is in place, it can be used for more than just basic account management. It can be useful for all sorts of niceties, such as automatic mailing list creation, LDAP services, and personal web page indexes.
Mentioning the creation of a separate database makes some people nervous. They think "Now I have to buy a really expensive commercial database, another machine for it to run on, and hire a database administrator." If you have thousands or tens of thousands of user accounts to manage, yes, you do need all of those things (though you may be able to get by with some of the noncommercial SQL databases like Postgres and MySQL). If this is the case for you, you may want to turn to Chapter 7, "SQL Database Administration", for more information on dealing with databases like this in Perl.
But in this chapter when I say database, I'm using the term in the broadest sense. A flat-file, plain text database will work fine for smaller installations. Win32 users could even use an access database file (e.g., database.mdb). For portability, we'll use plain text databases in this section for the different components we're going to build. To make things more interesting, our databases will be in XML format. If you have never encountered XML before, please take a moment to read Appendix C, "The Eight-Minute XML Tutorial".
Why XML? XML has a few properties that make it a good choice for files like this and other system administration configuration files:
XML is a plain text format, which means we can use our usual Perl bag o' tricks to deal with it easily.
XML is self-describing and practically self-documenting. With a character-delimited file like /etc/passwd, it is not always easy to determine which part of a line represents which field. With XML, this is never a problem because an obvious tag can surround each field.
With the right parser, XML can also be self-validating. If you use a validating parser, mistakes in an entry's format will be caught right away, since the file will not parse correctly according to its document type definition or schema. The Perl modules we'll be using in this chapter are based on a nonvalidating parser, but there is considerable work afoot (both within this framework and in other modules) to provide XML validation functionality. One step in this direction is XML::Checker, part of Enno Derksen's libxml-enno. Even without a validating parser, any XML parser that checks for well-formedness will catch many errors.
XML is flexible enough to describe virtually any set of text information you would ever desire to keep. This flexibility means you could use one parser library to get at all of your data, rather than having to write a new parser for each different format.
We'll use XML-formatted plain text files for the main user account storage file and the add/delete queues.
As we actually implement the XML portions of our account system, you'll find that the TMTOWTDI police are out in force. For each XML operation we require, we'll explore or at least mention several ways to perform it. Ordinarily when putting together a system like this, it would be better to limit our implementation options, but this way you will get a sense of the programming palette available when doing XML work in Perl.
Let's start by returning to the cliffhanger we left off with earlier in "NT 2000 User Rights." It mentioned we needed to write the account information we collected with CollectInformation( ) to our add queue file, but we didn't actually see code to perform this task. Let's look at how that XML-formatted file is written.
Using ordinary print statements to write an XML-compliant text would be the simplest method, but we can do better. Perl modules like XML::Generator by Benjamin Holzman and XML::Writer by David Megginson can make the process easier and less error-prone. They can handle details like start/end tag matching and escaping special characters (<, >, &, etc.) for us. Here's the XML writing code from our account system which makes use of XML::Writer:
sub AppendAccountXML {
# receive the full path to the file
my $filename = shift;
# receive a reference to an anonymous record hash
my $record = shift;
# XML::Writer uses IO::File objects for output control
use IO::File;
# append to that file
$fh = new IO::File(">>$filename") or
die "Unable to append to file:$!\n";
# initialize the XML::Writer module and tell it to write to
# filehandle $fh
use XML::Writer;
my $w = new XML::Writer(OUTPUT => $fh);
# write the opening tag for each <account> record
$w->startTag("account");
# write all of the <account> data start/end sub-tags & contents
foreach my $field (keys %{$record}){
print $fh "\n\t";
$w->startTag($field);
$w->characters($$record{$field});
$w->endTag;
}
print $fh "\n";
# write the closing tag for each <account> record
$w->endTag;
$w->end;
$fh->close( );
}
Now we can use just one line to collect data and write it to our add queue file:
&AppendAccountXML($addqueue,&CollectInformation);
Here's some sample output from this routine:[5]
[5]As a quick side note: the XML specification recommends that every XML file begin with a declaration (e.g., <?xml version="1.0"?>). It is not mandatory, but if we want to comply, XML::Writer offers the xmlDecl( )method to create one for us.
<account>
<login>bobf</login>
<fullname>Bob Fate</fullname>
<id>24-9057</id>
<type>staff</type>
<password>password</password>
<status>to_be_created</status>
</account>
Yes, we are storing passwords in clear text. This is an exceptionally bad idea for anything but a demonstration system and even then you should think twice. A real account system would probably pre-encrypt the password before adding it to the add queue or not keep this info in a queue at all.
AppendAccountXML( ) will make another appearance later when we want to write data to the end of our delete queue and our main account database.
The use of XML::Writer in our AppendAccountXML( ) subroutine gives us a few perks:
The code is quite legible; anyone with a little bit of markup language experience will instantly understand the names startTag( ), characters( ), and endTag( ).
Though our data didn't need this, characters( ) is silently performing a bit of protective magic for us by properly escaping reserved entities like the greater-than symbol (>).
Our code doesn't have to remember the last start tag we opened for later closing. XML::Writer handles this matching for us, allowing us to call endTag( ) without specifying which end tag we need. Keeping track of tag pairs is less of an issue with our account system because our data uses shallowly nesting tags, but this functionality becomes more important in other situations where our elements are more complex.
We'll see one more way of writing XML from Perl in a moment, but before we do, let's turn our attention to the process of reading all of the great XML we've just learned how to write. We need code that will parse the account addition and deletion queues and the main database.
It would be possible to cobble together an XML parser in Perl for our limited data set out of regular expressions, but that gets trickier as the XML data gets more complicated.[6] For general parsing, it is easier to use the XML::Parser module initially written by Larry Wall and now significantly enhanced and maintained by Clark Cooper.
[6]But it is doable; for instance, see Eric Prud'hommeaux's module at http://www.w3.org/1999/02/26-modules/W3C-SAX-XmlParser-*.
XML::Parser is an event-based module. Event-based modules work like stock market brokers. Before trading begins, you leave a set of instructions with them for actions they should take should certain triggers occur (e.g., sell a thousand shares should the price drop below 31⁄4, buy this stock at the beginning of the trading day, and so on). With event-based programs, the triggers are called events and the instruction lists for what to do when an event happens are called event handlers. Handlers are usually just special subroutines designed to deal with a particular event. Some people call them callback routines, since they are run when the main program "calls us back" after a certain condition is established. With the XML::Parser module, our events will be things like "started parsing the data stream," "found a start tag," and "found an XML comment," and our handlers will do things like "print the contents of the element you just found."[7]
[7]Though we don't use it here, Chang Liu's XML::Node module allows the programmer to easily request callbacks for only certain elements, further simplifying the process we're about to discuss.
Before we begin to parse our data, we need to create an XML::Parser object. When we create this object, we'll specify which parsing mode, or style, to use. XML::Parser provides several styles, each of which behaves a little different during the parsing of data. The style of a parse will determine which event handlers are called by default and the way data returned by the parser (if any) is structured.
Certain styles require that we specify an association between each event we wish to manually process and its handler. No special actions are taken for events we haven't chosen to explicitly handle. This association is stored in a simple hash table with keys that are the names of the events we want to handle, and values that are references to our handler subroutines. For the styles that require this association, we pass the hash in using a named parameter called Handlers (e.g., Handlers=>{Start=>\&start_handler}) when we create a parser object.
We'll be using the stream style that does not require this initialization step. It simply calls a set of predefined event handlers if certain subroutines are found in the program's namespace. The stream event handlers we'll be using are simple: StartTag, EndTag, and Text. All but Text should be self-explanatory. Text, according to the XML::Parser documentation, is "called just before start or end tags with accumulated non-markup text in the $_ variable." We'll use it when we need to know the contents of a particular element.
Here's the initialization code we're going to use for our application:
use XML::Parser;
use Data::Dumper; # used for debugging output, not needed for XML parse
$p = new XML::Parser(ErrorContext => 3,
Style => 'Stream',
Pkg => 'Account::Parse');
This code returns a parser object after passing in three named parameters. The first, ErrorContext, tells the parser to return three lines of context from the parsed data if an error should occur while parsing. The second sets the parse style as we just discussed. Pkg, the final parameter, instructs the parser to look in a different namespace than the current one for the event handler subroutines it expects to see. By setting this parameter, we've instructed the parser to look for &Account::Parse::StartTag(), &Account::Parse::EndTag( ), and so on, instead of just &StartTag( ), &EndTag( ), etc. This doesn't have any operational impact, but it does allow us to sidestep any concerns that our parser might inadvertently call someone else's function called StartTag( ). Instead of using the Pkg parameter, we could have put an explicit package Account::Parse; line before the above code.
Now let's look at the subroutines that perform the event handling functions. We'll go over them one at a time:
package Account::Parse;
sub StartTag {
undef %record if ($_[1] eq "account");
}
&StartTag( ) is called each time we hit a start tag in our data. It is invoked with two parameters: a reference to the parser object and the name of the tag encountered. We'll want to construct a new record hash for each new account record we encounter, so we can use StartTag( ) in order to let us know when we've hit the beginning of a new record (e.g., an <account> start tag). In that case, we obliterate any existing record hash. In all other cases we return without doing anything:
sub Text {
my $ce = $_[0]->current_element( );
$record{$ce}=$_ unless ($ce eq "account");
}
Here we use &Text( ) to populate the %record hash. Like the previous function, it too receives two parameters upon invocation: a reference to the parser object and the "accumulated nonmarkup text" the parser has collected between the last start and end tag. We determine which element we're in by calling the parser object's current_element( ) method. According to the XML::Parser::Expat documentation, this method "returns the name of the innermost currently opened element." As long as the current element name is not "account," we're sure to be within one of the subelements of <account>, so we record the element name and its contents:
sub EndTag {
print Data::Dumper->Dump([\%record],["account"])
if ($_[1] eq "account");
# here's where we'd actually do something, instead of just
# printing the record
}
Our last handler, &EndTag( ), is just like our first, &StartTag( ), except it gets called when we encounter an end tag. If we reach the end of an account record, we do the mundane thing and print that record out. Here's some example output:
$account = {
'login' => 'bobf',
'type' => 'staff',
'password' => 'password',
'fullname' => 'Bob Fate',
'id' => '24-9057'
};
$account = {
'login' => 'wendyf',
'type' => 'faculty',
'password' => 'password',
'fullname' => 'Wendy Fate',
'id' => '50-9057'
};
If we were really going to use this parse code in our account system we would probably call some function like CreateAccount(\%record) rather than printing the record using Data::Dumper.
Now that we've seen the XML::Parser initialization and handler subroutines, we need to include the piece of code that actually initiates the parse:
# handle multiple account records in a single XML queue file
open(FILE,$addqueue) or die "Unable to open $addqueue:$!\n";
# this clever idiom courtesy of Jeff Pinyan
read(FILE, $queuecontents, -s FILE);
$p->parse("<queue>".$queuecontents."</queue>");
This code has probably caused you to raise an eyebrow, maybe even two. The first two lines open our add queue file and read its contents into a single scalar variable called $queuecontents. The third line would probably be easily comprehensible, except for the funny argument being passed to parse( ). Why are we bothering to read in the contents of the actual queue file and then bracket it with more XML before actually parsing it?
Because it is a hack. As hacks go, it's not so bad. Here's why these convolutions are necessary to parse the multiple <account> elements in our queue file.
Every XML document, by definition (in the very first production rule of the XML specification), must have a root or document element. This element is the container element for the rest of the document; all other elements are subelements of it. An XML parser expects the first start tag it sees to be the start tag for the root element of that document and the last end tag it sees to be the end tag for that that element. XML documents that do not conform to this structure are not considered to be well-formed.
This puts us in a bit of a bind when we attempt to model a queue in XML. If we do nothing, <account> will be found as the first tag in the file. Everything will work fine until the parser hits the end </account> tag for that record. At that point it will cease to parse any further, even if there are more records to be found, because it believes it has found the end of the document.
We can easily put a start tag (<queue>) at the beginning of our queue, but how do we handle end tags (</queue>)? We always need the root element's end tag at the bottom of the file (and only there), a difficult task given that we're planning to repeatedly append records to this file.
A plausible but fairly heinous hack would be to seek( ) to the end of the file, and then seek( ) backwards until we backed up just before the last end tag. We could then write our new record over this tag, leaving an end tag at the end of the data we were writing. Just the risk of data corruption (what if you back up too far?) should dissuade you from this method. Also, this method gets tricky in cases where there is no clear end of file, e.g., if you were reading XML data from a network connection. In those cases you would probably need to do some extra shadow buffering of the data stream so it would be possible to back up from the end of transmission.
The method we demonstrated in the code above of prepending and appending a root element tag pair to the existing data may be a hack, but it comes out looking almost elegant compared to other solutions. Let's return to more pleasant topics.
We've seen one method for bare bones XML parsing using the XML::Parser module. To be true to our TMTOWTDI warning, let's revisit the task, taking an even easier tack. Several authors have written modules built upon XML::Parser to parse XML documents and return the data in easy-to-manipulate Perl object/data structure form, including XML::DOM by Enno Derksen, Ken MacLeod's XML::Grove and ToObjects (part of the libxml-perl package), XML::DT by Jose Joao Dias de Almeida, and XML::Simple by Grant McLean. Of these, XML::Simple is perhaps the easiest to use. It was designed to handle smallish XML configuration files, perfect for the task at hand.
XML::Simple provides exactly two functions. Here's the first (in context):
use XML::Simple;
use Data::Dumper; # just needed to show contents of our data structures
$queuefile = "addqueue.xml";
open(FILE,$queuefile) or die "Unable to open $queuefile:$!\n";
read(FILE, $queuecontents, -s FILE);
$queue = XMLin("<queue>".$queuecontents."</queue>");
We dump the contents of $queue, like so:
print Data::Dumper->Dump([$queue],["queue"]);
It is now a reference to the data found in our add queue file, stored as a hash of a hash keyed on our <id> elements. Figure 3-3 shows this data structure.

The data structure is keyed this way because XML::Simple has a feature that recognizes certain tags in the data, favoring them over the others during the conversion process. When we turn this feature off:
$queue = XMLin("<queue>".$queuecontents."</queue>",keyattr=>[]);
we get a reference to a hash with the sole value of a reference to an anonymous array. The anonymous array holds our data as seen in Figure 3-4.

That's not a particularly helpful data structure. We can tune the same feature in our favor:
$queue = XMLin("<queue>".$queuecontents."</queue>",keyattr => ["login"]);
Now we have a reference to a data structure (a hash of a hash keyed on the login name), perfect for our needs as seen in Figure 3-5.

How perfect? We can now remove items from our in-memory add queue after we process them with just one line:
# e.g. $login = "bobf";
delete $queue->{account}{$login};
If we want to change a value before writing it back to disk (let's say we were manipulating our main database), that's easy too:
# e.g. $login="wendyf" ; $field="status";
$queue->{account}{$login}{$field}="created";
The mention of "writing it back to disk" brings us to back the method of writing XML promised earlier. XML::Simple's second function takes a reference to a data structure and generates XML:
# rootname sets the root element's name, we could also use # xmldecl to add an XML declaration print XMLout($queue, rootname =>"queue");
This yields (indented for readability):
<queue>
<account name="bobf" type="staff"
password="password" status="to_be_created"
fullname="Bob Fate" id="24-9057" />
<account name="wendyf" type="faculty"
password="password" status="to_be_created"
fullname="Wendy Fate" id="50-9057" />
</queue>
This is perfectly good XML, but it's not in the same format as our data files. The data for each account is being represented as attributes of a single <account> </account> element, not as nested elements. XML::Simple has a set of rules for how it translates data structures. Two of these rules (the rest can be found in the documentation) can be stated as "single values are translated into XML attributes" and "references to anonymous arrays are translated as nested XML elements."
We need a data structure in memory that looks like Chapter 3, "User Accounts" to produce the "correct" XML output (correct means "in the same style and format as our data files").

Ugly, isn't it? We have a few choices at this point, including:
Changing the format of our data files. This seems a bit extreme.
Changing the way we ask XML::Simple to parse our file. To get an in-memory data structure like the one in Figure 3-6 we could use:
$queue = XMLin("<queue>".$queuecontents."</queue>",forcearray=>1,
keyattr => [""]);
But when we tailor the way we read in the data to make for easy writing, we lose our easy hash semantics for data lookup and manipulation.
Performing some data manipulation after reading but before writing. We could read the data into a structure we like (just like we did before), manipulate the data to our heart's contents, and then transform the data structure into one XML::Simple "likes" before writing it out.
Option number three appears to be the most reasonable, so let's pursue it. Here's a subroutine that takes the data structure in Chapter 3, "User Accounts" and transforms it into the data structure found in Chapter 3, "User Accounts". An explanation of this code will follow:
sub TransformForWrite{
my $queueref = shift;
my $toplevel = scalar each %$queueref;
foreach my $user (keys %{$queueref->{$toplevel}}){
my %innerhash =
map {$_,[$queueref->{$toplevel}{$user}{$_}] }
keys %{$queueref->{$toplevel}{$user}};
$innerhash{'login'} = [$user];
push @outputarray, \%innerhash;
}
$outputref = { $toplevel => \@outputarray};
return $outputref;
}
Let's walk through the TransformForWrite( ) subroutine one step at a time.
If you compare Figure 3-5 and Figure 3-6, you'll notice one common feature between these two structures: there is an outermost hash keyed with the same key (account). The following retrieves that key name by requesting the first key in the hash pointed to by $queueref:
my $toplevel = scalar each %$queueref;
Let's see how this data structure is created from the inside out:
my %innerhash =
map {$_,[$queueref->{$toplevel}{$user}{$_}] }
keys %{$queueref->{$toplevel}{$user}};
This piece of code uses map( ) to iterate over the keys found in the innermost hash for each entry (i.e., login, type, password, status). The keys are returned by:
keys %{$queueref->{$toplevel}{$user}};
As we iterate over each key, we ask map to return two values for each key: the key itself, and the reference to an anonymous array that contains the value of this key:
map {$_,[$queueref->{$toplevel}{$user}{$_}] }
The list returned by map( ) looks like this:
(login,[bobf], type,[staff], password,[password]...)
It has a key-value format, where the values are stored as elements in anonymous arrays. We can simply assign this list to %innerhash to populate the inner hash table for our resulting data structure (my %innerhash =). We also add a login key to that hash based on the current user being processed:
$innerhash{'login'} = [$user];
The data structure we are trying to create is a list of hashes like these, so after we create and populate our inner hash, we add a reference to it on to the end of our output structure list:
push @outputarray, \%innerhash;
We repeat this procedure once for every login key found in our original data structure (once per account record). When we are done, we have a list of references to hashes in the form we need. We create an anonymous hash with a key that is the same as the outermost key for the original data structure and a value that is our list of hashes. We return a reference to this anonymous hash back to the caller of our subroutine, and we're done:
$outputref = { $toplevel => \@outputarray};
return $outputref;
With &TransformForWrite( ), we can now write code to read in, manipulate, and then write out our data:
$queue = XMLin("<queue>".$queuecontents."</queue>",keyattr => ["login"]);
manipulate the data...
print OUTPUTFILE XMLout(TransformForWrite($queue),rootname => "queue");
The data written will be in the same format as the data read.
Before we move on from the subject of reading and writing data, let's tie up some loose ends:
Eagle-eyed readers may notice that using XML::Writer and XML::Simple in the same program to write to our account queue could be problematic. If we write with XML::Simple, our data will be nested in a root element by default. If we write using XML::Writer (or with just print statements), that's not necessarily the case, meaning we need to resort to the "<queue>".$queuecontents."</queue>" hack. We have an undesirable level of reader-writer synchronization between our XML parsing and writing code.
To get around this, we will have to use an advanced feature of XML::Simple: if XMLout( ) is passed a rootname parameter with a value that is empty or undef, it will produce XML code that does not have a root element. In most cases this is a dangerous thing to do because it means the XML being produced is not well-formed and will not be parseable. Our queue-parsing hack allows us to get away with it, but in general this is not a feature you want to invoke lightly
Though we didn't do this in our sample code, we should be ready to deal with parsing errors. If the data file contains non-well-formed data, then your parser will sputter and die (as per the XML specification), taking your whole program with it unless you are careful. The most common way to deal with this in Perl is to wrap your parse statement in eval( ) and then check the contents of $@ after the parse completes.[8] For example:
[8]Daniel Burckhardt pointed out on the Perl-XML list that this method has its drawbacks. In a multithreaded Perl program, checking the global $@ may not be safe without taking other precautions. Threading issues like this were still under discussion among the Perl developers at the time of this publishing.
eval {$p->parse("<queue>".$queuecontents."</queue>")};
if ($@) { do something graceful to handle
the error before quitting...
};
Another solution would be to use something like the XML::Checker module mentioned before, since it handles parse errors with more grace.
Now that we have all of the data under control, including how it is acquired, written, read, and stored, let's look at how it is actually used deep in the bowels of our account system. We're going to explore the code that actually creates and deletes users. The key to this section is the notion that we are building a library of reusable components. The better you are able to compartmentalize your account system routines, the easier it will be to change only small pieces when it comes time to migrate your system to some other operating system or make changes. This may seem like unnecessary caution on our part, but the one constant in system administration work is constant change.
Let's begin with the code that handles Unix account creation. Most of this code will be pretty trivial because we're going to take the easy way out. Our account creation and deletion routines will call vendor-supplied "add user," "delete user," and "change password" executables with the right arguments.
Why the apparent cop-out? We are using this method because we know the OS-specific executable will play nice with the other system components. Specifically, this method:
Handles the locking issues for us (i.e., avoids the data corruption problems, that two programs simultaneously trying to write to the password file can cause).
Handles the variations in password file formats (including password encoding) we discussed earlier.
Is likely to be able to handle any OS-specific authentication schemes or password distribution mechanisms. For instance, under Digital Unix, the external "add user" executable can add directly add a user to the NIS maps on a master server.
Drawbacks of using an external binary to create and remove accounts include:
Each OS has a different set of binaries, located at a different place on the system, which take slightly different arguments. In a rare show of compatibility, almost all of the major Unix variants (Linux included, BSD variants excluded) have mostly compatible add and remove account binaries called useradd and userdel. The BSD variants use adduser and rmuser, two programs with similar purpose but very different argument names. Variations like this tend to increase the complexity of our code.
The program we call and the arguments passed to it will be exposed to users wielding the ps command. If accounts are only created on a secure machine (like a master server), this reduces the data leakage risk considerably.
If the executable changes for some reason or is moved, our account system is kaput.
We have to treat a portion of the account creation process as being atomic; in other words, once we run the executable we can't intervene or interleave any of our own operations. Error detection and recovery becomes more difficult.
It's likely these programs will not perform all of the steps necessary to instantiate an account at your site. Perhaps you need to add specific user types to specific auxiliary groups, place users on a site-wide mailing list, or add users to a license file for a commercial package. You'll have to add some more code to handle these specifities. This isn't a problem with the approach itself, it's more of a heads up that any account system you build will probably require more work on your part than just calling another executable. This will not surprise most system administrators, since system administration is very rarely a walk in the park.
For the purposes of our demonstration account system, the positives of this approach outweigh the negatives, so let's see some code that uses external executables. To keep things simple, we're going to show code that works under Solaris and Linux on a local machine only, ignoring complexities like NIS and BSD variations. If you'd like to see a more complex example of this method in action, you may find the CfgTie family of modules by Randy Maas instructive.
Here's our basic account creation routine:
# these variables should really be set in a central configuration file
$useraddex = "/usr/sbin/useradd"; # location of useradd executable
$passwdex = "/bin/passwd"; # location of passwd executable
$homeUnixdirs = "/home"; # home directory root dir
$skeldir = "/home/skel"; # prototypical home directory
$defshell = "/bin/zsh"; # default shell
sub CreateUnixAccount{
my ($account,$record) = @_;
### construct the command line, using:
# -c = comment field
# -d = home dir
# -g = group (assume same as user type)
# -m = create home dir
# -k = and copy in files from this skeleton dir
# (could also use -G group, group, group to add to auxiliary groups)
my @cmd = ($useraddex,
"-c", $record->{"fullname"},
"-d", "$homeUnixdirs/$account",
"-g", $record->{"type"},
"-m",
"-k", $skeldir,
"-s", $defshell,
$account);
print STDERR "Creating account...";
my $result = 0xff & system @cmd;
# the return code is 0 for success, non-0 for failure, so we invert
if ($result){
print STDERR "failed.\n";
return "$useraddex failed";
}
else {
print STDERR "succeeded.\n";
}
print STDERR "Changing passwd...";
unless ($result = &InitUnixPasswd($account,$record->{"password"})){
print STDERR "succeeded.\n";
return "";
}
else {
print STDERR "failed.\n";
return $result;
}
}
This adds the appropriate entry to our password file, creates a home directory for the account, and copies over some default environment files (.profile, .tcshrc, .zshrc, etc.) from a skeleton directory.
Notice we make a separate subroutine call to handle setting a password for the account. The useradd command on some operating systems (like Solaris) will leave an account in a locked state until the passwd command is run for that account. This process requires a little sleight of hand, so we encapsulate that step in a separate subroutine to keep the details out of our way. We'll see that subroutine in just a moment, but first for symmetry's sake here's the simpler account deletion code:
# these variables should really be set in a central configuration file
$userdelex = "/usr/sbin/userdel"; # location of userdel executable
sub DeleteUnixAccount{
my ($account,$record) = @_;
### construct the command line, using:
# -r = remove the account's home directory for us
my @cmd = ($userdelex, "-r", $account);
print STDERR "Deleting account...";
my $result = 0xffff & system @cmd;
# the return code is 0 for success, non-0 for failure, so we invert
if (!$result){
print STDERR "succeeded.\n";
return "";
}
else {
print STDERR "failed.\n";
return "$userdelex failed";
}
}
Before we move on to NT account operations, let's deal with the InitUnixPasswd( ) routine we mentioned earlier. To finish creating an account (under Solaris, at least), we need to change that account's password using the standard passwd command. passwd<accountname> will change that account's password.
Sounds simple, but there's a problem lurking here. The passwd command expects to prompt the user for the password. It takes great pains to make sure it is talking to a real user by interacting directly with the user's terminal device. As a result, the following will not work:
# this code DOES NOT WORK open(PW,"|passwd $account"); print PW $oldpasswd,"\n"; print PW $newpasswd,"\n";
We have to be craftier than usual; somehow faking the passwd program into thinking it is dealing with a human rather than our Perl code. We can achieve this level of duplicity by using Expect.pm, a Perl module by Austin Schutz that sets up a pseudo-terminal (pty) within which another program will run. Expect.pm is heavily based on the famous Tcl program Expect by Don Libes. This module is part of the family of bidirectional program interaction modules. We'll see its close relative, Jay Rogers's Net::Telnet, in Chapter 6, "Directory Services".
These modules function using the same basic conversational model: wait for output from a program, send it some input, wait for a response, send some data, and so on. The code below starts up passwd in a pty and waits for it to prompt for the password. The discussion we have with passwd should be easy to follow:
use Expect;
sub InitUnixPasswd {
my ($account,$passwd) = @_;
# return a process object
my $pobj = Expect->spawn($passwdex, $account);
die "Unable to spawn $passwdex:$!\n" unless (defined $pobj);
# do not log to stdout (i.e. be silent)
$pobj->log_stdout(0);
# wait for password & password re-enter prompts,
# answering appropriately
$pobj->expect(10,"New password: ");
# Linux sometimes prompts before it is ready for input, so we pause
sleep 1;
print $pobj "$passwd\r";
$pobj->expect(10, "Re-enter new password: ");
print $pobj "$passwd\r";
# did it work?
$result = (defined ($pobj->expect(10, "successfully changed")) ?
"" : "password change failed");
# close the process object, waiting up to 15 secs for
# the process to exit
$pobj->soft_close( );
return $result;
}
The Expect.pm module meets our meager needs well in this routine, but it is worth noting that the module is capable of much more complex operations. See the documentation and tutorial included with the Expect.pm module for more information.
The process of creating and deleting an account under Windows NT/2000 is slightly easier than the process under Unix because standard API calls for the operation exist under NT. Like Unix, we could call an external executable to handle the job (e.g., the ubiquitous net command with its USERS/ADD switch), but it is easy to use the native API calls from a handful of different modules, some we've mentioned earlier. Account creation functions exist in Win32::NetAdmin, Win32::UserAdmin, Win32API::Net, and Win32::Lanman, just to start. Windows 2000 users will find the ADSI material in Chapter 6, "Directory Services" to be their best route.
Picking among these NT4-centric modules is mostly a matter of personal preference. In order to understand the differences between them, we'll take a quick look behind the scenes at the native user creation API calls. These calls are documented in the Network Management SDK documentation on http://msdn.microsoft.com (search for "NetUserAdd" if you have a hard time finding it). NetUserAdd( ) and the other calls take a parameter that specifies the information level of the data being submitted. For instance, with information level 1, the C structure that is passed in to the user creation call looks like this:
typedef struct _USER_INFO_1 {
LPWSTR usri1_name;
LPWSTR usri1_password;
DWORD usri1_password_age;
DWORD usri1_priv;
LPWSTR usri1_home_dir;
LPWSTR usri1_comment;
DWORD usri1_flags;
LPWSTR usri1_script_path;
}
If information level 2 is used, the structure expected is expanded considerably:
typedef struct _USER_INFO_2 {
LPWSTR usri2_name;
LPWSTR usri2_password;
DWORD usri2_password_age;
DWORD usri2_priv;
LPWSTR usri2_home_dir;
LPWSTR usri2_comment;
DWORD usri2_flags;
LPWSTR usri2_script_path;
DWORD usri2_auth_flags;
LPWSTR usri2_full_name;
LPWSTR usri2_usr_comment;
LPWSTR usri2_parms;
LPWSTR usri2_workstations;
DWORD usri2_last_logon;
DWORD usri2_last_logoff;
DWORD usri2_acct_expires;
DWORD usri2_max_storage;
DWORD usri2_units_per_week;
PBYTE usri2_logon_hours;
DWORD usri2_bad_pw_count;
DWORD usri2_num_logons;
LPWSTR usri2_logon_server;
DWORD usri2_country_code;
DWORD usri2_code_page;
}
Without having to know anything about these parameters, or even much about C at all, we can still tell that a change in level increases the amount of information that can be specified as part of the user creation. Also, each subsequent information level is a superset of the previous one.
What does this have to do with Perl? Each module mentioned makes two decisions:
Should the notion of "information level" be exposed to the Perl programmer?
Which information level (i.e., how many parameters) can the programmer use?
Win32API::Net and Win32::UserAdmin both allow the programmer to choose an information level. Win32::NetAdmin and Win32::Lanman do not. Of the modules, Win32::NetAdmin exposes the least number of parameters; for example, you cannot set the full_name field as part of the user creation call. If you choose to use Win32::NetAdmin, you will probably have to supplement it with calls from another module to set the additional parameters it does not expose. If you do go with a combination like Win32::NetAdmin and Win32::AdminMisc, you'll want to consult the Roth book mentioned earlier, because it is an excellent reference for the documentation-impoverished Win32::NetAdmin module.
Now you have some idea why the module choice really boils down to personal preference. A good strategy might be to first decide which parameters are important to you, and then find a comfortable module that supports them. For our demonstration subroutines below, we're going to arbitrarily pick Win32::Lanman. Here's the user creation and deletion code for our account system:
use Win32::Lanman; # for account creation
use Win32::Perms; # to set the permissions on the home directory
$homeNTdirs = "\\\\homeserver\\home"; # home directory root dir
sub CreateNTAccount{
my ($account,$record) = @_;
# create this account on the local machine
# (i.e., empty first parameter)
$result = Win32::Lanman::NetUserAdd("",
{'name' => $account,
'password' => $record->{password},
'home_dir' => "$homeNTdirs\\$account",
'full_name' => $record->{fullname}});
return Win32::Lanman::GetLastError( ) unless ($result);
# add to appropriate LOCAL group (first get the SID of the account)
# we assume the group name is the same as the account type
die "SID lookup error: ".Win32::Lanman::GetLastError( )."\n" unless
(Win32::Lanman::LsaLookupNames("", [$account], \@info));
$result = Win32::Lanman::NetLocalGroupAddMember("",$record->{type},
${$info[0]}{sid});
return Win32::Lanman::GetLastError( ) unless ($result);
# create home directory
mkdir "$homeNTdirs\\$account",0777 or
return "Unable to make homedir:$!";
# now set the ACL and owner of the directory
$acl = new Win32::Perms("$homeNTdirs\\$account");
$acl->Owner($account);
# we give the user full control of the directory and all of the
# files that will be created within it (hence the two separate calls)
$acl->Allow($account, FULL, DIRECTORY|CONTAINER_INHERIT_ACE);
$acl->Allow($account, FULL,
FILE|OBJECT_INHERIT_ACE|INHERIT_ONLY_ACE);
$result = $acl->Set( );
$acl->Close( );
return($result ? "" : $result);
}
The user deletion code looks like this:
use Win32::Lanman; # for account deletion
use File::Path; # for recursive directory deletion
sub DeleteNTAccount{
my($account,$record) = @_;
# remove user from LOCAL groups only. If we wanted to also
# remove from global groups we could remove the word "Local" from
# the two Win32::Lanman::NetUser* calls (e.g., NetUserGetGroups)
die "SID lookup error: ".Win32::Lanman::GetLastError( )."\n" unless
(Win32::Lanman::LsaLookupNames("", [$account], \@info));
Win32::Lanman::NetUserGetLocalGroups($server, $account,'', \@groups);
foreach $group (@groups){
print "Removing user from local group ".$group->{name}."...";
print(Win32::Lanman::NetLocalGroupDelMember("",
$group->{name),
${$info[0]}{sid}) ?
"succeeded\n" : "FAILED\n");
}
# delete this account on the local machine
# (i.e., empty first parameter)
$result = Win32::Lanman::NetUserDel("", $account);
return Win32::Lanman::GetLastError( ) if ($result);
# delete the home directory and its contents
$result = rmtree("$homeNTdirs\\$account",0,1);
# rmtree returns the number of items deleted,
# so if we deleted more than 0,it is likely that we succeeded
return $result;
As a quick aside, the above code uses the portable File::Path module to remove an account's home directory. If we wanted to do something Win32-specific, like move the home directory to the Recycle Bin instead, we could use a module called Win32::FileOp by Jenda Krynicky, at http://jenda.krynicky.cz/. In this case, we'd use Win32::FileOp and change the rmtree( ) line to:
# will move directory to the Recycle Bin, potentially confirming
# the action with the user if our account is set to confirm
# Recycle Bin actions
$result = Recycle("$homeNTdirs\\$account");
This same module also has a Delete( ) function that will perform the same operation as the rmtree( ) call above in a less portable (although quicker) fashion.
Once we have a backend database, we'll want to write scripts that encapsulate the day-to-day and periodic processes that take place for user administration. These scripts are based on a low-level component library (Account.pm) we created by concatenating all of the subroutines we just wrote together into one file. To make sure all of the modules we need are loaded, we'll add this subroutine:
sub InitAccount{
use XML::Writer;
$record = { fields => [login,fullname,id,type,password]};
$addqueue = "addqueue"; # name of add account queue file
$delqueue = "delqueue"; # name of del account queue file
$maindata = "accountdb"; # name of main account database file
if ($^O eq "MSWin32"){
require Win32::Lanman;
require Win32::Perms;
require File::Path;
# location of account files
$accountdir = "\\\\server\\accountsystem\\";
# mail lists, example follows
$maillists = "$accountdir\\maillists\\";
# home directory root
$homeNTdirs = "\\\\homeserver\\home";
# name of account add subroutine
$accountadd = "CreateNTAccount";
# name of account del subroutine
$accountdel = "DeleteNTAccount";
}
else {
require Expect;
# location of account files
$accountdir = "/usr/accountsystem/";
# mail lists, example follows
$maillists = "$accountdir/maillists/";
# location of useradd executable
$useraddex = "/usr/sbin/useradd";
# location of userdel executable
$userdelex = "/usr/sbin/userdel";
# location of passwd executable
$passwdex = "/bin/passwd";
# home directory root dir
$homeUnixdirs = "/home";
# prototypical home directory
$skeldir = "/home/skel";
# default shell
$defshell = "/bin/zsh";
# name of account add subroutine
$accountadd = "CreateUnixAccount";
# name of account del subroutine
$accountdel = "DeleteUnixAccount";
}
}
Let's see some sample scripts. Here's the script that processes the add queue:
use Account;
use XML::Simple;
&InitAccount; # read in our low level routines
&ReadAddQueue; # read and parse the add account queue
&ProcessAddQueue; # attempt to create all accounts in the queue
&DisposeAddQueue; # write account record either to main database or back
# to queue if there is a problem
# read in the add account queue to the $queue data structure
sub ReadAddQueue{
open(ADD,$accountdir.$addqueue) or
die "Unable to open ".$accountdir.$addqueue.":$!\n";
read(ADD, $queuecontents, -s ADD);
close(ADD);
$queue = XMLin("<queue>".$queuecontents."</queue>",
keyattr => ["login"]);
}
# iterate through the queue structure, attempting to create an account
# for each request (i.e., each key) in the structure
sub ProcessAddQueue{
foreach my $login (keys %{$queue->{account}}){
$result = &$accountadd($login,$queue->{account}->{$login});
if (!$result){
$queue->{account}->{$login}{status} = "created";
}
else {
$queue->{account}->{$login}{status} = "error:$result";
}
}
}
# now iterate through the queue structure again. For each account with
# a status of "created," append to main database. All others get written
# back to the add queue file, overwriting it.
sub DisposeAddQueue{
foreach my $login (keys %{$queue->{account}}){
if ($queue->{account}->{$login}{status} eq "created"){
$queue->{account}->{$login}{login} = $login;
$queue->{account}->{$login}{creation_date} = time;
&AppendAccountXML($accountdir.$maindata,
$queue->{account}->{$login});
delete $queue->{account}->{$login};
next;
}
}
# all we have left in $queue at this point are the accounts that
# could not be created
# overwrite the queue file
open(ADD,">".$accountdir.$addqueue) or
die "Unable to open ".$accountdir.$addqueue.":$!\n";
# if there are accounts that could not be created write them
if (scalar keys %{$queue->{account}}){
print ADD XMLout(&TransformForWrite($queue),rootname => undef);
}
close(ADD);
}
Our "process the delete user queue file" script is similar:
use Account;
use XML::Simple;
&InitAccount; # read in our low level routines
&ReadDelQueue; # read and parse the add account queue
&ProcessDelQueue; # attempt to delete all accounts in the queue
&DisposeDelQueue; # write account record either to main database or back
# to queue if there is a problem
# read in the del user queue to the $queue data structure
sub ReadDelQueue{
open(DEL,$accountdir.$delqueue) or
die "Unable to open ${accountdir}${delqueue}:$!\n";
read(DEL, $queuecontents, -s DEL);
close(DEL);
$queue = XMLin("<queue>".$queuecontents."</queue>",
keyattr => ["login"]);
}
# iterate through the queue structure, attempting to delete an account for
# each request (i.e. each key) in the structure
sub ProcessDelQueue{
foreach my $login (keys %{$queue->{account}}){
$result = &$accountdel($login,$queue->{account}->{$login});
if (!$result){
$queue->{account}->{$login}{status} = "deleted";
}
else {
$queue->{account}->{$login}{status} = "error:$result";
}
}
}
# read in the main database and then iterate through the queue
# structure again. For each account with a status of "deleted," change
# the main database information. Then write the main database out again.
# All that could not be deleted are written back to the del queue
# file, overwriting it.
sub DisposeDelQueue{
&ReadMainDatabase;
foreach my $login (keys %{$queue->{account}}){
if ($queue->{account}->{$login}{status} eq "deleted"){
unless (exists $maindb->{account}->{$login}){
warn "Could not find $login in $maindata\n";
next;
}
$maindb->{account}->{$login}{status} = "deleted";
$maindb->{account}->{$login}{deletion_date} = time;
delete $queue->{account}->{$login};
next;
}
}
&WriteMainDatabase;
# all we have left in $queue at this point are the accounts that
# could not be deleted
open(DEL,">".$accountdir.$delqueue) or
die "Unable to open ".$accountdir.$addqueue.":$!\n";
# if there are accounts that could not be created, else truncate
if (scalar keys %{$queue->{account}}){
print DEL XMLout(&TransformForWrite($queue),rootname => undef);
}
close(DEL);
}
sub ReadMainDatabase{
open(MAIN,$accountdir.$maindata) or
die "Unable to open ".$accountdir.$maindata.":$!\n";
read (MAIN, $dbcontents, -s MAIN);
close(MAIN);
$maindb = XMLin("<maindb>".$dbcontents."</maindb>",
keyattr => ["login"]);
}
sub WriteMainDatabase{
# note: it would be *much, much safer* to write to a temp file
# first and then swap it in if the data was written successfully
open(MAIN,">".$accountdir.$maindata) or
die "Unable to open ".$accountdir.$maindata.":$!\n";
print MAIN XMLout(&TransformForWrite($maindb),rootname => undef);
close(MAIN);
}
There are many other process scripts you could imagine writing. For example, we could certainly use scripts that perform data export and consistency checking (e.g., does the user's home directory match up with the main databases account type? Is that user in the appropriate group?). We don't have space to cover this wide range of programs, so let's end this section with a single example of the data export variety. Earlier we mentioned that a site might want a separate mailing list for each type of user on the system. The following code reads our main database and creates a set of files that contain user names, one file per user type:
use Account; # just to get the file locations
use XML::Simple;
&InitAccount;
&ReadMainDatabase;
&WriteFiles;
# read the main database into a hash of lists of hashes
sub ReadMainDatabase{
open(MAIN,$accountdir.$maindata) or
die "Unable to open ".$accountdir.$maindata.":$!\n";
read (MAIN, $dbcontents, -s MAIN);
close(MAIN);
$maindb = XMLin("<maindb>".$dbcontents."</maindb>",keyattr => [""]);
}
# iterate through the lists, compile the list of accounts of a certain
# type and store them in a hash of lists. Then write out the contents of
# each key to a different file.
sub WriteFiles {
foreach my $account (@{$maindb->{account}}){
next if $account->{status} eq "deleted";
push(@{$types{$account->{type}}},$account->{login});
}
foreach $type (keys %types){
open(OUT,">".$maillists.$type) or
die "Unable to write to ".$accountdir.$maillists.$type.": $!\n";
print OUT join("\n",sort @{$types{$type}})."\n";
close(OUT);
}
}
If we look at the mailing list directory, we see:
> dir faculty staff
And each one of those files contains the appropriate list of user accounts.
Now that we've seen four components of an account system, let's wrap up this section by talking about what's missing (besides oodles of functionality):
Our demonstration code has only a modicum of error checking. Any self-respecting account system would grow another 40-50% in code size because it would check for data and system interaction problems every step of the way.
Our code could probably work in a small-to mid-sized environment. But any time you see "read the entire file into memory," it should set off warning bells. To scale we would need to change our data storage and retrieval techniques at the very least. The module XML::Twig by Michel Rodriguez may help with this problem, since it works with large, well-formed XML documents without reading them into memory all at once.
This is related to the very first item on error checking. Besides truck-sized security holes like the storage of plain text passwords, we also do not perform any security checks in our code. We do not confirm that the data sources we use like the queue files are trustworthy. Add another 20-30% to the code size to take care of this issue.
We make no provision for multiple users or even multiple scripts running at once, perhaps the largest flaw in our code as written. If the "add account" process script is being run at the same time as the "add to the queue" script, the potential for data loss or corruption is very high. This is such an important issue that we should take a few moments to discuss it before concluding this section.
One way to help with the multiuser deficiency is to carefully introduce file locking. File locking allows the different scripts to cooperate. If a script plans to read or write to a file, it can attempt to lock the file first. If it can obtain a lock, then it knows it is safe to manipulate the file. If it cannot lock the file (because another script is using it), it knows not to proceed with an operation that could corrupt data. There's considerably more complexity involved with locking and multiuser access in general than just this simple description reveals; consult any fundamental Operating or Distributed Systems text. It gets especially tricky when dealing with files residing on network filesystems, where there may not be a good locking mechanism. Here are a few hints that may help you when you approach this topic using Perl.
There are smart ways to cheat. My favorite method is to use the lockfile program distributed with the popular mail filtering program procmail found at http://www.procmail.org. The procmail installation procedure takes great pains to determine safe locking strategies for the filesystems you are using. lockfile does just what its name suggests, hiding most of the complexity in the process.
If you don't want to use an external executable, there are a plethora of locking modules available. For example, File::Flock by David Muir Sharnoff, File::LockDir from the Perl Cookbook by Tom Christiansen and Nathan Torkington (O'Reilly), and a Win95/98 version of it by William Herrera called File::FlockDir, File::Lock by Kenneth Albanowski, File::Lockf by Paul Henson, and Lockfile::Simple by Raphael Manfredi. They differ mostly in interface, though File::FlockDir and Lockfile::Simple attempt to perform locking without using Perl's flock( ) function. This is useful for platforms like MacOS that don't support that function. Shop around and pick the best one for your needs.
Locking is easier to get right if you remember to lock before attempting to change data (or read data that could change) and only unlock after making sure that data has been written (e.g., after the file has been closed). For more information on this, see the previously mentioned Perl Cookbook, the Perl Frequently Asked Questions list, and the documentation that comes with Perl on the flock( ) function and the DB_File module.
This ends our look at user account administration and how it can be taken to the next level using a bit of an architectural mindset. In this chapter we've concentrated on the beginning and the end of an account's lifecycle. In the next chapter, we'll examine what users do in between these two points.
|  | |
| 3.2. Windows NT/2000 User Identity |  | 3.4. Module Information for This Chapter |

Copyright © 2001 O'Reilly & Associates. All rights reserved.
HIVE: All information for read only. Please respect copyright! |

