 | Perl for System Administration |

The Simple Network Management Protocol (SNMP) is the ubiquitous protocol used to manage devices on a network. Unfortunately, as we metioned at the beginning of Chapter 10, "Security and Network Monitoring", SNMP is not a particularly simple protocol (despite its name). This longish tutorial will give you the information you need to get started with Version 1 of SNMP.
SNMP is predicated on the notion that you have a management station that polls an SNMP agent running on a remote device for information. The agent can also be instructed to signal the management station if an important condition arises (like a counter exceeding a threshold). When we programmed in Perl in Chapter 10, "Security and Network Monitoring", we essentially acted as a management station, polling the SNMP agents on other network devices.
We're going to concentrate on Version 1 of SNMP. There have been seven versions of the protocol (SNMPv1, SNMPsec, SNMPv2p, SNMPv2c, SNMPv2u, SNMPv2* and SNMPv3) proposed. v1 is the only one that has been widely implemented and deployed, though v3 is expected to eventually ascend thanks to its superior security architecture.
Perl and SNMP both have simple data types. Perl uses a scalar as its base type. Lists and hashes are just collections of scalars in Perl. In SNMP, you also work with scalar variables. SNMP variables can hold one of four primitive types: integers, strings, object identifiers (more on this in a moment), or null values. And just like Perl, in SNMP a set of related variables can be grouped together to form larger structures (most often tables). This is where their similarity ends.
Perl and SNMP diverge radically when we come to the subject of variable names. In Perl, you can, given a few restrictions, name your variables anything you'd like. SNMP variable names are considerably more restrictive. All SNMP variables exist within a virtual hierarchical storage structure known as the Management Information Base (MIB). All valid variable names are defined within this framework. The MIB, now at version MIB-II, defines a tree structure for all of the objects (and their names) that can be managed via SNMP.
In some ways the MIB is similar to a filesystem. Instead of organizing files, the MIB logically organizes management information in a hierarchical tree-like structure. Each node in this tree has a short text string, called a label, and an accompanying number that represents its position at that level in the tree. To give you a sense of how this works, let's go find the SNMP variable in the MIB used to hold a system's description of itself. Bear with me; we have a bit of a tree walking (eight levels' worth) to get there.
Figure E-1 shows a picture of the top of the MIB tree.
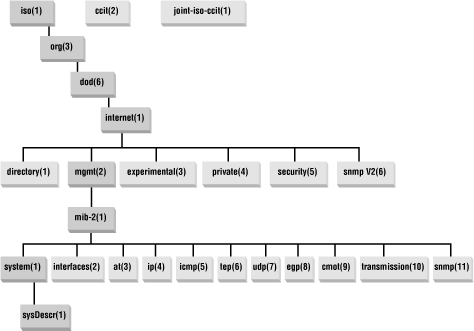
The top of the tree consists of standards organizations: iso(1),ccitt(2),joint-iso-ccitt(3). Under the iso(1) node, there is a node called org(3) for other organizations. Under this node is dod(6), for the Department of Defense. Under that node is internet(1), a subtree for the Internet community.
Here's where things start to get interesting. The Internet Activities Board has assigned the subtrees listed in Table E-1 under internet(1).
|
Subtree |
Description |
|---|---|
|
directory(1) |
OSI directory |
|
mgmt(2) |
RFC standard objects |
|
experimental(3) |
Internet experiments |
|
private(4) |
Vendor-specific |
|
security(5) |
Security |
|
snmpV2(6) |
SNMP internals |
Because we're interested in using SNMP for device management, we will want to take the mgmt(2) branch, The first node under mgmt(2) is the MIB itself (this is almost recursive). Since there is only one MIB, the only node under mgmt(2) is mib-2(1).
The real meat (or tofu) of the MIB begins at this level in the tree. We find the first set of branches, called object groups, that hold the variables we'll want to query:
system(1) interfaces(2) at(3) ip(4) icmp(5) tcp(6) udp(7) egp(8) cmot(9) transmission(10) snmp(11)
Remember, we're hunting for the "system description" SNMP variable, so the system(1) group is the logical place to look. The first node in that tree is sysDescr(1). We've located the object we need.
Why bother with all of this tree-walking stuff? This trip provides us with sysDescr(1)'s Object Identifier. The Object Identifier, or OID, is just the dotted set of the numbers from each label of the tree we encountered on our way to this object. Figure E-2 shows this graphically.
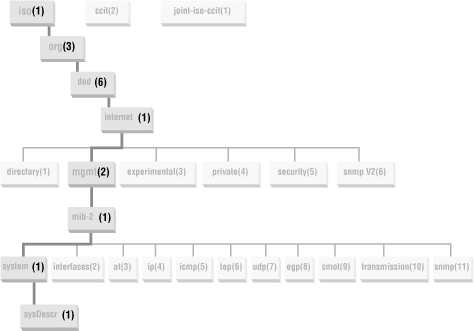
So the OID for the Internet tree is 1.3.6.1, the OID for the system object group is 1.3.6.1.2.1.1, and the OID for the sysDescr object is 1.3.6.1.2.1.1.1.
When we want to actually use this OID in practice, we'll need to tack on another number to get the value of this variable. We will need to append a .0, representing the first (and only, since a device cannot have more than one description) instance of this object.
In fact, let's do that; let's use this OID in a sneak preview of SNMP in action. In this appendix we'll be using the command-line tools from the UCD-SNMP package for demonstration purposes. The UCD-SNMP package that can be found at http://ucd-snmp.ucdavis.edu/ is an excellent free SNMPv1 and v3 implementation. We're using this particular SNMP implementation because one of the Perl modules links to its library, but any other client that can send an SNMP request will do just as nicely. Once you're familiar with command-line SNMP utilities, making the jump to the Perl equivalents is easy.
The UCD-SNMP command-line tools require us to prepend a dot if we wish to specify an OID/variable name starting at the root of the tree. Otherwise the OID/variable name is assumed to begin at the top of the mib-2 tree. Here are two ways we might query the machine solarisbox for its systems description:
$ snmpget solarisbox public .1.3.6.1.2.1.1.1.0 $ snmpget solarisbox public .iso.org.dod.internet.mgmt.mib-2.system.sysDescr.0
These lines both yield:
system.sysDescr.0 = Sun SNMP Agent, Ultra-1
Back to the theory. It is important to remember that the P in SNMP stands for Protocol. SNMP itself is just the protocol for the communication between entities in a management infrastructure. The operations, or "protocol data units" (PDUs), are meant to be simple. Here are the PDUs you'll see most often, especially when programming in Perl:[1]
[1]The canonical list of PDUs is found in RFC1905 for SNMPv2 and v3, which builds upon the PDUs in SNMPv1's RFC1157. The RFC list isn't much bigger than the PDUs cited here, so you're not missing much.
get-request is the workhorse of the PDU family. get-request is used to poll an SNMP entity for the value of some SNMP variable. Many people live their whole SNMP lives using nothing but this operation.
get-next-request is just like get-request, except it returns the item in the MIB just after the specified item (the "first lexicographic successor" in RFC terms). This operation comes into play most often when you are attempting to find all of the items in a logical table object. For instance, you might send a set of repeated get-next-requests to query for each line of a workstation's ARP table. We'll see an example of this in practice in a moment.
set-request does just what you would anticipate; it attempts to change the value of an SNMP variable. This is the operation used to change the configuration of an SNMP-capable device.
trap is the SNMPv1 name, and snmpV2-trap is the SNMPv2/3 name. Traps are beyond the scope of this book, but in essence they allow you to ask an SNMP-capable box to signal its management entity about an event (like a reboot, or a counter threshold being reached) without being explicitly polled.
response is the PDU used to carry the response back from any of the other PDUs. It can be used to reply to a get-request, signal if a set-request succeeded, and so on. You rarely reference this PDU explicitly when programming, since most SNMP libraries, programs, and Perl modules automatically handle SNMP response receipt. Still, it is important to understand not just how requests are made, but also how they are answered.
If you've never dealt with SNMP before, a natural reaction to the above list might be "That's it? Get, set, tell me when something happens, that's all it can do?" But simple, as SNMP's creators realized early on, is not the opposite of powerful. If the manufacturer of an SNMP device chooses her or his variables well, there's little that cannot be done with the protocol. The classic example from the RFCs is the rebooting of an SNMP-capable device. There may be no "reboot-request" PDU, but a manufacturer could easily implement this operation by using an SNMP trigger variable to hold the number of seconds before a reboot. When this variable is changed via set-request, a reboot of the device could be initiated in the specified amount of time.
Given this power, what sort of security is in place to keep anyone with an SNMP client from rebooting your machine? In earlier versions of the protocol, the protection mechanism was pretty puny. In fact, some people have taken to expanding the acronym as "Security Not My Problem" because of SNMPv1's poor authentication mechanism. To explain the who, what, and how of this protection mechanism, we have to drag out some nomenclature, so bear with me.
SNMPv1 and SNMPv2C allow you to define administrative relationships between SNMP entities called communities. Communities are a way of grouping SNMP agents that have similar access restrictions with the management entities that meet those restrictions. All entities that are in a community share the same community name. To prove you are part of a community, you just have to know the name of that community. That is the who can access? part of the scheme.
For the "what can they access?" part, RFC1157 calls the parts of a MIB applicable to a particular network entity an SNMP MIB view. For instance, an SNMP-capable toaster[2] would not provide all of the same SNMP configuration variables as that of an SNMP-capable router.
[2]There's an SNMP-capable Coke machine (information on it is available at http://www.nixu.fi/limu), so it isn't all that farfetched.
Each object in a MIB is defined as being accessible read-only, read-write, or none. This is known as that object's SNMP access mode. If we put an SNMP MIB view and an SNMP access mode together, we get an SNMP community profile that describes the type of access available to the applicable variables in the MIB by a particular community.
Now we bring the who and the what parts together and we have an SNMP access policy that describes what kind of access members of a particular community offer each other.
How does this all work in real life? You configure your router or your workstation to be in at least two communities, one controlling read, the other controlling read-write access. People often refer to these communities as the public and the private communities, named after popular default names for these communities. For instance, on a Cisco router you might include this as part of the configuration:
! set the read-only community name to MyPublicCommunityName snmp-server community MyPublicCommunityName RO ! set the read-write community name to MyPrivateCommunityName snmp-server community MyPrivateCommunityName RW
On a Solaris machine, you might include this in the /etc/snmp/conf/snmpd.conf file:
read-community MyPublicCommunityName write-community MyPrivateCommunityName
SNMP queries to either of these devices would have to use the MyPublicCommunityName community name to gain access to read-only variables or the MyPrivateCommunityName community names to change read-write variables on those devices. The community name is then functioning as a pseudo-password to gain SNMP access to a device. This is a poor security scheme. Not only is the community name passed in clear text in every SNMP packet, but it is trying to protect access using "security by obscurity."
Later versions of SNMP, Version 3 in particular, added significantly better security to the protocol. RFC2274 and RFC2275 define a User Security Model (USM) and a View-Based Access Control (VACM) Model. USM provides crypto-based protection for authentication and encryption of messages. VACM offers a comprehensive access control mechanism for MIB objects. These mechanisms are still relatively new and unimplemented (for instance, only one of the available Perl modules supports it, and this support is very new). We won't be discussing these mechanisms here, but it is probably worth your while to peruse the RFCs since v3 is increasing in popularity.
Now that you've received a healthy dose of SNMP theory, let's do something practical with this knowledge. You've already seen how to query a machine's system description (remember the sneak preview earlier). Now let's look at two more examples: querying the system uptime and the IP routing table.
Until now, you just had to take my word for the location and name of an SNMP variable in the MIB. We need to change that, since the first step in querying information via SNMP is a process I call "MIB groveling:"
Find the right MIB document. If you are looking for a device-independent setting that could be found on any generic SNMP device, you will probably find it in RFC1213.[3] If you need vendor-specific variable names, e.g., the variable that holds "the color of a blinky-light on the front panel of a specific ATM switch," you will need to contact the vendor of the switch and request a copy of their MIB module. I'm being pedantic about the terms here because it is not uncommon to hear people incorrectly say, "I need the MIB for that device." There is only one MIB in the world; everything else fits somewhere in that structure (usually off of the private(4) branch).
[3]RFC1213 is marginally updated by RFC2011, RFC2012, and RFC2013. RFC1907 adds additional SNMPv2 items to the MIB.
Search through MIB descriptions until you find the SNMP variable(s) you need.
To make this second step easier for you, let me help decode the format.
MIB descriptions aren't all that scary once you get used to them. They look like one long set of variable declarations similar to those you would find in source code. This is no coincidence because they are variable declarations. If a vendor has been responsible in the construction of its module, that module will be heavily commented like any good source code file.
MIB information is written in a subset of Abstract Syntax Notation One (ASN.1), an Open Systems Interconnection (OSI) standard notation. A description of this subset and other details of the data descriptions for SNMP are found in RFCs called Structure for Management Information (SMI) RFCs. These accompany the RFCs that define the SNMP protocol and the current MIB. For instance, the latest (as of this writing) SNMP protocol definition can be found in RFC1905, the latest base MIB manipulated by this protocol is in RFC1907, and the SMI for this MIB is in RFC2578. I bring this to your attention because it is not uncommon to have to flip between several documents when looking for specifics on an SNMP subject.
Let's use this knowledge to address the first task at hand: finding the system uptime of a machine via SNMP. This information is fairly generic, so there's a good chance we can find the SNMP variable we need in RFC1213. A quick search for "uptime" in RFC1213 yields this snippet of ASN.1:
sysUpTime OBJECT-TYPE
SYNTAX TimeTicks
ACCESS read-only
STATUS mandatory
DESCRIPTION
"The time (in hundredths of a second) since the
network management portion of the system was last
re-initialized."
::= { system 3 }
Let's take this definition apart line by line:
This defines the object called sysUpTime.
This object is of the type TimeTicks. Object types are specified in the SMI we mentioned a moment ago.
This object can only be read via SNMP (i.e., get-request); it cannot be changed (i.e., set-request).
This object must be implemented in any SNMP agent.
This is a textual description of the object. Always read this field carefully. In this definition, there's a surprise in store for us. sysUpTime only shows the amount of time that has elapsed since "the network management portion of the system was last re-initialized." This means we're only going to be able to tell a system's uptime since its SNMP agent was last started. This is almost always the same as when the system itself last started, but if you spot an anomaly, this could be the reason.
Here's where this object fits in the MIB tree. The sysUpTime object is the third branch off of the system object group tree. This information also gives you part of the Object Identifier should you need it later.
If we wanted to query this variable on the machine solarisbox in the read-only community, we could use the following UCD-SNMP tool command line:
$ snmpget solarisbox MyPublicCommunityName system.sysUpTime.0
This returns:
system.sysUpTime.0 = Timeticks: (5126167) 14:14:21.67
The agent was last initialized fourteen hours ago.
TIP
The examples in this appendix assume our SNMP agents have been configured to allow requests from the querying host. In general, if you can restrict SNMP access to a certain subset of "trusted" hosts, you should.
"Need to know" is an excellent security principle to follow. It is good practice to restrict the network services provided by each machine and device. If you do not need to provide a network service, turn it off. If you do need to provide it, restrict the access to only the devices that "need to know."
Time for our second and more advanced SNMP example: dumping the contents of a device's IP routing table. The complexity in this example comes from the need to treat a collection of scalar data as a single logical table. We'll have to invoke the get-next-request PDU to pull this off. Our first step towards this goal is to look for a MIB definition of the IP routing table. Searching for "route" in RFC1213, we eventually find this definition:
-- The IP routing table contains an entry for each route
-- presently known to this entity.
ipRouteTable OBJECT-TYPE
SYNTAX SEQUENCE OF IpRouteEntry
ACCESS not-accessible
STATUS mandatory
DESCRIPTION
"This entity's IP Routing table."
::= { ip 21 }
This doesn't look much different from the definition we took apart just a moment ago. The differences are in the ACCESS and SYNTAX lines. The ACCESS line is a tip-off that this object is just a structural placeholder representing the whole table, and not a real variable that can be queried. The SYNTAX line tells us this is a table consisting of a set of IpRouteEntry objects. Let's look at the beginning of the IpRouteEntry definition:
ipRouteEntry OBJECT-TYPE
SYNTAX IpRouteEntry
ACCESS not-accessible
STATUS mandatory
DESCRIPTION
"A route to a particular destination."
INDEX { ipRouteDest }
::= { ipRouteTable 1 }
The ACCESS line says we've found another placeholder--the placeholder for each of the rows in our table. But this placeholder also has something to tell us. It indicates that we'll be able to access each row by using an index object, the ipRouteDest object of each row.
If these multiple definition levels throw you, it may help to relate this to Perl. Pretend we're dealing with a Perl hash of lists structure. The hash key for the row would be the ipRouteDest variable. The value for this hash would then be a reference to a list containing the other elements in that row (i.e., the rest of the route entry).
The ipRouteEntry definition continues as follows:
ipRouteEntry ::=
SEQUENCE {
ipRouteDest
IpAddress,
ipRouteIfIndex
INTEGER,
ipRouteMetric1
INTEGER,
ipRouteMetric2
INTEGER,
ipRouteMetric3
INTEGER,
ipRouteMetric4
INTEGER,
ipRouteNextHop
IpAddress,
ipRouteType
INTEGER,
ipRouteProto
INTEGER,
ipRouteAge
INTEGER,
ipRouteMask
IpAddress,
ipRouteMetric5
INTEGER,
ipRouteInfo
OBJECT IDENTIFIER
}
Now you can see the elements that make up each row of the table. The MIB continues by describing those elements. Here are the first two definitions for these elements:
ipRouteDest OBJECT-TYPE
SYNTAX IpAddress
ACCESS read-write
STATUS mandatory
DESCRIPTION
"The destination IP address of this route. An
entry with a value of 0.0.0.0 is considered a
default route. Multiple routes to a single
destination can appear in the table, but access to
such multiple entries is dependent on the table-
access mechanisms defined by the network
management protocol in use."
::= { ipRouteEntry 1 }
ipRouteIfIndex OBJECT-TYPE
SYNTAX INTEGER
ACCESS read-write
STATUS mandatory
DESCRIPTION
"The index value which uniquely identifies the
local interface through which the next hop of this
route should be reached. The interface identified
by a particular value of this index is the same
interface as identified by the same value of
ifIndex."
::= { ipRouteEntry 2 }
Figure E-3 shows a picture of the ipRouteTable part of the MIB to help summarize all of this information.
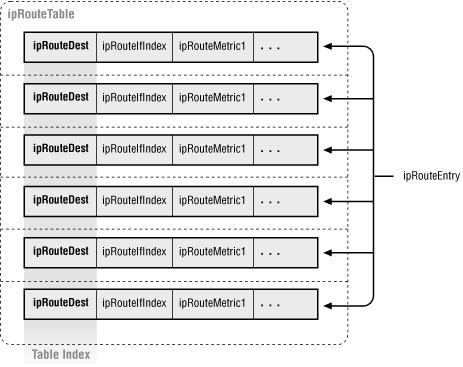
Once you understand this part of the MIB, the next step is querying the information. This is a process known as "table traversal." Most SNMP packages have a command-line utility called something like snmptable or snmp-tbl that will perform this process for you, but they might not offer the granularity of control you need. For instance, you may not want a dump of the whole routing table; you may just want a list of all of the ipRouteNextHops. On top of this, some of the Perl SNMP packages do not have tree-walking routines. For all of these reasons, it is worth knowing how to perform this process by hand.
To make this process easier to understand, I'll show you up front the information we're eventually going to be receiving from the device. This will let you see how each step of the process adds another row to the table data we'll collect. If I log into a sample machine (as opposed to using SNMP to query it remotely) and type netstat -nr to dump the IP routing table, the output might look like this:
default 192.168.1.1 UGS 0 215345 tu0 127.0.0.1 127.0.0.1 UH 8 5404381 lo0 192.168.1/24 192.168.1.189 U 15 9222638 tu0
This shows the default internal loopback and local network routes, respectively.
Now let's see how we go about obtaining a subset of this information via the UCD-SNMP command-line utilities. For this example, we're only going to concern ourselves with the first two columns of the output above (route destination and next hop address). We make an initial request for the first instance of those two variables in the table. Everything in bold type is one long command line and is only printed here on separate lines for legibility:
$ snmpgetnext computer public ip.ipRouteTable.ipRouteEntry.ipRouteDest ip.ipRouteTable.ipRouteEntry.ipRouteNextHop ip.ipRouteTable.ipRouteEntry.ipRouteDest.0.0.0.0 = IpAddress: 0.0.0.0 ip.ipRouteTable.ipRouteEntry.ipRouteNextHop.0.0.0.0 = IpAddress: 192.168.1.1
There are two parts of this response we need to pay attention to. The first is the actual data, the information returned after the equals sign. 0.0.0.0 means "default route," so the information returned corresponded to the first line of the routing table output above. The second important part of the response is the .0.0.0.0 tacked on to the variable names above. This is the index for the ipRouteEntry entry representing the table row.
Now that we have the first row, we can make another get-next-request call, this time using the index. A get-next-request always returns the next item in a MIB, so we feed it the index of the row we just received so we can get back the next row after it:
$ snmpgetnext gold public ip.ipRouteTable.ipRouteEntry.ipRouteDest.0.0.0.0 ip.ipRouteTable.ipRouteEntry.ipRouteNextHop.0.0.0.0 ip.ipRouteTable.ipRouteEntry.ipRouteDest.127.0.0.1 = IpAddress: 127.0.0.1 ip.ipRouteTable.ipRouteEntry.ipRouteNextHop.127.0.0.1 = IpAddress: 127.0.0.1
You can probably guess the next step. We issue another get-next-request using the 127.0.0.1 part (the index) of the ip.ipRouteTable.ipRouteEntry.ipRouteDest.127.0.0.1 response:
$ snmpgetnext gold public ip.ipRouteTable.ipRouteEntry.ipRouteDest.127.0.0.1 ip.ipRouteTable.ipRouteEntry.ipRouteNextHop.127.0.0.1 ip.ipRouteTable.ipRouteEntry.ipRouteDest.192.168.1 = IpAddress: 192.168.1.0 ip.ipRouteTable.ipRouteEntry.ipRouteNextHop.192.168.11.0 = IpAddress: 192.168.1.189
Looking at the sample netstat output above, you can see we've achieved our goal and dumped all of the rows of the IP routing table. How would we know this if we had dispensed with the dramatic irony and hadn't seen the netstat output ahead of time? Under normal circumstances we would have to proceed as usual and continue querying:
$ snmpgetnext gold public ip.ipRouteTable.ipRouteEntry.ipRouteDest.192.168.1.0 ip.ipRouteTable.ipRouteEntry.ipRouteNextHop.192.168.1.0 ip.ipRouteTable.ipRouteEntry.ipRouteIfIndex.0.0.0.0 = 1 ip.ipRouteTable.ipRouteEntry.ipRouteType.0.0.0.0 = indirect(4)
Whoops, the response did not match the request! We asked for ipRouteDest and ipRouteNextHop but got back ipRouteIfIndex and ipRouteType. We've fallen off the edge of the ipRouteTable table. The SNMP get-next-request PDU has done its sworn duty and returned the "first lexicographic successor" in the MIB for each of the objects in our request. Looking back at the definition of ipRouteEntry in the excerpt from RFC1213 above, we can see that ipRouteIfIndex(2) follows ipRouteDest(1), and ipRouteType(8) does indeed follow ipRouteNextHop(7).
The answer to the question we asked a moment ago, "How do you know when you are done querying for the contents of a table?" is "When you notice you've fallen off the edge of that table." Programmatically, this translates into checking that the same string or OID prefix you requested is returned in the answer to your query. For instance, you might make sure that all responses to a query about ipRouteDest contained either ip.ipRouteTable.ipRouteEntry.ipRouteDest or 1.3.6.1.2.1.4.21.1.1.
Now that you have the basics of SNMP under your belt, you may want to turn to Chapter 10, "Security and Network Monitoring" to see how we can use it from Perl. You should also check out the references at the end of Chapter 10, "Security and Network Monitoring" for more information on SNMP.
|  | |
| D.6. SQL Stragglers |  |

Copyright © 2001 O'Reilly & Associates. All rights reserved.
HIVE: All information for read only. Please respect copyright! |

