| 7.14. Применение регулярных выражений | ||
|---|---|---|
 | Глава 7. Базовые навыки работы в Unix |  |
| 7.14. Применение регулярных выражений | ||
|---|---|---|
| | Глава 7. Базовые навыки работы в Unix | |
Описание: Работа с регулярными выражениями является частью повседневной работы системного администратора. Кандидат BSDA должен быть способен искать текстовые шаблоны при анализе вывода программ или поиске в файлах. Кандидат должен уметь указать диапазон символов в скобках [], определить литерал (?!), использовать квантификаторы, отличать метасимволы и создавать инвертированные фильтры.
Практика: grep(1), egrep(1), fgrep(1), re_format(7).
Регулярные выражения это то, с чем администратор имеет дело почти ежеминутно. В этом вопросе безусловно нужна практика. Вместе с тем, чтобы полностью описать всё богатство возможностей регулярных выражений, все их недостатки, плюсы и минусы различных механизмов поиска, нужно потратить годы. К счастью, в нашем распоряжении есть перевод замечательной книги Дж. Фридла «Регулярные выражения» [Friedl-2001-ru]. К сожалению, издатели не планируют переиздавать её, однако любезно выложили для всеобщего использования текст этой книги. Вот небольшая цитата из предисловия к этой книге:
Небольшой тест — попробуйте определить понятие «между». Помните: определяемое слово не может использоваться в определении! Ну как, получилось? Нет? Действительно, задача не из простых. Хорошо, что смысл этого слова понятен всем, иначе нам пришлось бы подолгу разъяснять его всем несведущим. Даже такие простые концепции бывает трудно описать кому-то, кто еще не знаком с ними.
До определенной степени сказанное относится и к регулярным выражениям. На самом деле регулярные выражения не так сложны, как их описания и объяснения.
С другой стороны, положа руку на сердце, для задач администрироания не нужно прибегать ко всему богатству возможностей регулярных выражений. От администратора требуется лишь знание основных синтаксических конструкций, а в данном разделе я явно вышел за рамки того, что реально нужно в работе администратору. Web-программисту и, тем более, для верстальщику в LaTeX'е требуется больше.
Итак, регулярные выражения — это способ описания текста и манипулирования с ним. При помощи регулярных выражений вы можете создавать шаблоны для поиска нужных вам фрагментов текста.
Реальный пример: допустим вам нужно найти все IP-адреса, с
которых на вашу машину пытались пройти используя несуществующие
имена пользователей. Для этой цели вы можете изучить журнальный
файл /var/log/auth.log разыскивая сообщения
демона sshd, содержащие слова «Invalid
user»:
$ awk '/sshd.*Invalid user/{print $10}' /var/log/auth.log | sort | uniq
125.243.235.194
193.158.246.173
218.248.33.225
Здесь команда awk(1) вырезает 10-й столбец из
всех строк, которые соответствуют регулярному выражению sshd.*Invalid user. Конструкция .* означает сколько угодно чего угодно.
Т.е. мы ищем в журнальном файле строку в которой написано sshd
затем возможно какие-то ещё слова и цифры и Invalid user.
Это тривиальный пример, но такие тривиальные примеры рождаются каждую минуту. Он написан очень просто, хотя и не очень корректно. На реальном журнальном файле вероятность сбоя такого регулярного выражения исчисляется сотыми долями процента, так как сам журнальный файл написан автоматом и имеет строго определённый формат. Менее тривиальные примеры в администраторской практике появляются редко и нужны скорее при написании каких-то служебных программ. Например: найти на диске скрипты в которых утилита env(1) используется для вызова программ по неабсолютному пути. (Чем это может быть опасно рассматривается в Раздел 7.2.1.1, «env(1), printenv(1)».) Поскольку таких программ будет найдено во множестве, мы ограничились лишь первыми десятью в качестве примера.
$find / -type f -perm +a+x -print0 2>/dev/null | \>xargs -0 egrep '/usr/bin/env +([^ ]+=[^ ]* +)*[^/][^=]+( |$)' | head /usr/local/lib/python2.4/test/pystone.py:#! /usr/bin/env python /usr/local/lib/python2.4/test/re_tests.py:#!/usr/bin/env python /usr/local/lib/python2.4/test/regrtest.py:#! /usr/bin/env python /usr/local/lib/python2.4/test/test_al.py:#! /usr/bin/env python /usr/local/lib/python2.4/test/test_array.py:#! /usr/bin/env python /usr/local/lib/python2.4/test/test_binhex.py:#! /usr/bin/env python /usr/local/lib/python2.4/test/test_bsddb.py:#! /usr/bin/env python /usr/local/lib/python2.4/test/test_cd.py:#! /usr/bin/env python /usr/local/lib/python2.4/test/test_cl.py:#! /usr/bin/env python /usr/local/lib/python2.4/test/test_cmath.py:#! /usr/bin/env python
Регулярное выражение, написанное в аргументе команды
egrep(1): /usr/bin/env +([^ ]+=[^ ]* +)*[^/][^=]+( |$)
«переводится» на русский язык следующим образом: мы
ищем текст /usr/bin/env, за которым возможно идёт несколько
объявлений содержащих в себе знак равенства (т.е. объявление что
некоторая переменная окружения равна какому-то значению), после
которой идёт слово не содержащее в себе знак равенства и
начинающееся не со знака / (т.е. не являющееся абсолютным
путём). Разберём подробнее (если вы не знакомы с синтаксисом
регулярных выражений, переходите к следующему подразделу, а потом
вернитесь):
/usr/bin/env +/usr/bin/env, за которым идёт не менее
одного пробела.
([^ ]+=[^ ]* +)*[^/][^=]+( |$)
Первое впечатление от всего этого механизма состоит в том, что перед нами некоторое глобальное жульничество. Между прочим, так оно и есть.
![[Важно]](images/important.png) | Важно |
|---|---|
| Помните: регулярные выражения это удобный, но ненадёжный способ поиска. Как правило они ищут не то, что от них просят, а то, что удобнее искать. |
Автор данного текста, однажды, по заданию издательства URSS, писал регулярное выражение для поиска фамилий и инициалов в тексте. Этот труд занял несколько дней. 90% времени ушло на тестирование и, в результате, полученный монстр работал с КПД не более 98%. В мире есть множество весьма необычных фамилий и вариантов написания инициалов, а так же разнообразнах приставок вроде фон-, ван-дер-, де-, ибн- и т.п.
Многие регулярные выражения могут и должны писаться автоматически. Мне приходилось видеть работу регулярного выражения длиной 2 мегабайта. Ничего, живенько работало. Однако, это не прерогатива системного администратора. Просто, для программистов скажу, что если вы можете заменить регулярное выражение стековой машиной — сделайте это. Стековая машина работает намного корректнее и часто быстрее, хотя и требует большего количества телодвижений.
| Важно |
|---|---|
| Существуют задачи принципиально не имеющие решения в рамках механизма регулярных выражений. Например, поскольку регулярное выражение не может считать сколько конструкций оно захватило, с его помощью невозможно в общем виде решить задачу поиска ответной скобки, хотя и можно решить частный случай, когла известно, что глубина вложенности скобок не превышает n. В общем случае задача поиска ответной скобки, это задача для стековой машины. |
Регулярное выражение для поиска ответной фигурной скобки при условии ограниченной вложенности скобок, написанное на perl(1):
{[^{}]*} 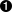 {([^{}]*|{[^{}]*})*}
{([^{}]*|{[^{}]*})*} 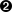 {([^{}]*|{([^{}]*|{[^{}]*})*})*}
{([^{}]*|{([^{}]*|{[^{}]*})*})*}  {([^{}]*|{([^{}]*|{([^{}]*|{[^{}]*})*})*})*}
{([^{}]*|{([^{}]*|{([^{}]*|{[^{}]*})*})*})*} 
Заметим, что начиная с некоторого уровня вложенности у этого регулярного выражения начнутся явные проблемы с производительностью, кроме того, существует некоторая критическая величина вложенности круглых скобок, при которой у интерпретатора окажется превышен лимит рекурсии.
Однако вернёмся к нашему регулярному выражению для поиска
«плохих» скриптов: /usr/bin/env +([^ ]+=[^ ]* +)*[^/][^=]+( |$).
Что если записать его попроще? Давайте сравним его с вот таким
регулярным выражением: /usr/bin/env +[^/]. Мы убрали из
регулярного выражения весь его «ум». А теперь давайте
посмотрим правде в глаза: 1) этот ум был несовершенен
(например, он не учитывал ситуацию, когда вызов
env(1) и утилиты были бы записаны на разных
строках, через обратный слеш); 2) результат ухудшится не
более чем на 1-2%, так как ситуация, когда определяется какая-то
переменная редка.
Мораль: будьте проще и не зацикливайтесь на регулярных выражениях.
К сожалению, от программы к программе часто меняются не только возможности регулярных выражений, но и их синтаксис. Стало быть, нам понадобится некоторая сводная таблица.
В первом столбце этой таблицы приведён синтаксис языка программирования perl(1). Этот диалект весьма распространён, встречается он и в других языках, например в python(1).
Второй столбец посвящён регулярным выражениям редактора vim(1). Не путайте его с vi(1). Возможности vi(1) намного скромнее. По поводу vim(1) хочется заметить вот что: здесь не перечислено и половины его возможностей. Это самый богатый диалект регулярных выражений, который я знаю, даже богаче perl(1). Но это же и самый медленный диалект.
grep(1) и egrep(1)
представленные в третьем и четвёртом столбцах, являются одной
и той же программой. egrep(1) это
grep(1) вызванный с опцией
-E, и хотя в man(1)
сказано, что эта опция включает расширенные регулярные
выражения, ничего она не включает, это не более чем
переключатель синтаксиса (см. ниже).
Синтаксис регулярных выражений grep(1) совпадает с синтаксисом таких утилит, как sed(1) или awk(1), так как они слинкованы с той же библиотекой регулярных выражений, и описан в re_format(7), хотя и весьма не наглядно. (Точнее, синтаксис sed(1) совпадает с синтаксисом grep(1), а синтаксис регулярных выражений awk(1) совпадает с синтаксисом egrep(1).) Кроме того, поскольку эти программы вызываются из разнообразных скриптов, (например apropos(1), это скрипт Bourne shell), то регулярные выражения grep(1) реально используются много где, даже если в документации про это ничего не сказано.
Таблица 7.14. Регулярные выражения. Сводная синтаксическая таблица
| perl(1) | vim(1) | grep(1) | egrep(1) | Описание |
|---|---|---|---|---|
| Классы | ||||
[a-zA-Z] | [a-zA-Z] | [a-zA-Z] | [a-zA-Z] | Класс. Соответствие символу указанному в наборе, можно указывать диапазоны. В примере описано множество букв |
[^a-zA-Z] | [^a-zA-Z] | [^a-zA-Z] | [^a-zA-Z] | Инвертированный класс. Соответствие символу остутствующему в указанном в наборе. В примере описано множество небукв |
| Предопределённые классы (список неполон) | ||||
. | . | . | . | Любой символ |
\w | \w | [[:alnum:]_] | [[:alnum:]_] | Алфавитно-цифровой символ и подчерк (word) |
\W | \W | [^[:alnum:]_] | [^[:alnum:]_] | Множество дополнительное множеству word |
\d | \d | [[:digit:]] | [[:digit:]] | Цифры |
\D | \D | [^[:digit:]] | [^[:digit:]] | Не цифры |
\s | \s | [[:space:]] | [[:space:]] | Пробельные символы (пробел, табулятор, и т.п.) |
\S | \S | [^[:space:]] | [^[:space:]] | Непробельные символы символы |
| Квантификаторы «жадные» | ||||
* | * | * | * | Повтор предыдущего символа 0 и более раз |
+ | \+ | \+ | + | Повтор предыдущего символа 1 и более раз |
? | \? | \? | ? | Повтор предыдущего символа 0 или 1 раз |
{n,m} | \{n,m} | \{n,m\} | {n,m} | Повтор предыдущего символа от n до m раз |
{n,} | \{n,} | \{n,\} | {n,} | Повтор предыдущего символа минимум n раз |
{n} | \{n} | \{n\} | {n} | Повтор предыдущего символа строго n раз |
| Квантификаторы «нежадные» | ||||
*? | \{-} | Повтор предыдущего символа 0 и более раз, но как можно меньше | ||
+? | \{-1,} | Повтор предыдущего символа 1 и более раз, но как можно меньше | ||
{n,m}? | \{-n,m} | Повтор предыдущего символа от n до m раз, но как можно меньше | ||
{n,}? | \{-n,} | Повтор предыдущего символа минимум n раз, но как можно меньше | ||
| Специальные позиции | ||||
^ | ^ | ^ | ^ | Начало строки |
$ | $ | $ | $ | Конец строки |
\b | \< | \< | \< | Левая граница слова |
\b | \> | \> | \> | Правая граница слова |
\B | Позиция не являющаяся границей слова | |||
(?=atom) | atom\@= | Заглядывание вперёд. Позиция за которой идёт atom. В vim(1) атом имеет право быть переменной длины, в perl(1) это не так. | ||
(?!atom) | atom\@! | Заглядывание вперёд. Позиция за которой нет atom'а | ||
(?<=atom) | atom\@<= | Заглядывание назад. Позиция перед которой есть atom | ||
(?<!atom) | atom\@<! | Заглядывание назад. Позиция перед которой нет atom'а | ||
При помощи заглядываний вперёд или назад можно
пытаться найти некоторый текст не содержащий заданного
слова. Например, шаблон <section>(.(?!<section\b))*</section>
ищет текст от <section> до
</section>, если
внутри него не случилось другого тега <section
| ||||
| Или | ||||
| | \| | \| | | | Оператор «или» |
| Группировка | ||||
() | \(\) | \(\) | () |
Группа: 1) ограничивает действие оператора
«или»: «Слава (КПСС|КПРФ)»
2) объединяет различные атомы вместе так, чтобы к
ним можно было применить общий квантификатор,
3) кроме того, впоследствии на текст
соответствующий группе можно ссылаться по номеру (все
группы последовательно нумеруются, а попавший в группу
текст запоминается).
|
(?:...) | \%(...\) | Ненумерующаяся группа | ||
\n | \n | \n | \n |
Ссылка на группу номер n: выражение ([a-z])\1 ищет удвоенные буквы.
Заметьте, это не то же саме, что [a-z]{2}, которое ище две
буквы, даже, если они неодинаковые.
|
Шаблоны встречающиеся в командной строке sh(1) тоже в некотором смысле являются регулярными выражениями.
Есть только одно обстоятельство, которое регулярным выражением так просто не записать: шаблоны Bourne shell не ищут совпадения с файлами начинающимися с точки, если это не указано явно.
В BSD установлен GNU grep(1).
Опции команды grep(1) можно ражделить на несколько типов: 1) синтаксические опции; 2) формат вывода: опции влияющие на характер выводимой информации; 3) опции влияющие на то где осуществляется поиск.
-E, --extended-regex-F, --fixed-strings-i, --ignore-case-w, --word-regexpgrep -w
grep найдёт слово grep, не не найдёт egrep.
-x, --line-regexp-v, --invert-matchegrep -v '^(#|$)' test.sh
напечатает непустые строки, в которых нет комментария.
-v, --invert-matchegrep -v '^(#|$)' test.sh
напечатает непустые строки, в которых нет комментария.
-C [NUM], -NUM, --context[=NUM]-A NUM, --after-context=NUM, -B NUM, --before-context=NUM-c, --count-H, --with-filename-h, --no-filename-l, --files-with-matches-L, --files-without-matches-b, --byte-offset-n, --line-number-q, --quiet, --silent, -s, --no-messages-q подавляет вывод
информации на STDOUT, а
-s на STDERR. В
man(1) содержится рекомендация не
использовать эти опции при написании скриптов, которые
должны быть абсолютно переносимыми, пользуясь вместо них
обычным перенаправлением вывода.
--null-print0 команды
find(1) и предназначено для
ассоциации с командой xargs(1). (см.
Раздел 7.15, «Преодоление ограничений на длину командной строки» и Раздел 7.6.3, «Связка с командой xargs»)
-r, --recursive-d recurse.
Возможно более разумно пользоваться связкой
find-xargs-grep, во всяком случае, это надёжнее. Если
вас посетила идея искать слово во всех файлах
компьютера, то команда find / -type f -print0 |
xargs -0 grep pattern имеет шансы успешно
завершиться, чего не приходится ожидать от команды
grep pattern -r / — такая
команда в лучшем случае повиснет. Опцию
-r имеет смысл применять лишь на
небольших файловых иерархиях, про которые вы можете
уверенно сказать, что в них нет симлинков ведущих
наружу, а так же файлов устройств.
-d ACTION, --directories=ACTIONACTION равно skip,
ничего не делать, если
read — искать в них как в
файлах, если recurse,
grep(1) рекурсивно ищет во всех
файлах, встретившихся в данном каталоге и во всех
подкаталогах. См. так же замечание к предыдущей опции.
-a, --text, --binary-files=text-I, --files-without-match,
--binary-files=without-match--binary-files=TYPETYPE. Значения text и
without-match только что были описаны,
по умолчанию используется значение
binary, означающее, что при наличии
совпадения будет выдано соответствующее сообщение из
одной строки.

| |  | |
| 7.13. Использование контроля за задачами (job control) |  | 7.15. Преодоление ограничений на длину командной строки |
HIVE: All information for read only. Please respect copyright! |


![[+]](images/button-green.png) 7.14.1. Диалекты регулярных выражений
7.14.1. Диалекты регулярных выражений