C.2. Конфигурационный файл pf.conf(5) | ||
|---|---|---|
 | Приложение C. Пакетный фильтр OpenBSD — pf(4) |  |
C.2. Конфигурационный файл pf.conf(5) | ||
|---|---|---|
| | Приложение C. Пакетный фильтр OpenBSD — pf(4) | |
![[+]](images/button-blue.png) C.2.1. Основы конфигурирования пакетного фильтраC.2.1.1. СпискиC.2.1.2. МакросыC.2.1.3. ТаблицыC.2.1.4. Фильтрация пакетовC.2.1.4.1. Синтаксис правилC.2.1.4.2. ПолитикаC.2.1.4.3. Пропускаем трафикC.2.1.4.4. Ключевое слово
C.2.1. Основы конфигурирования пакетного фильтраC.2.1.1. СпискиC.2.1.2. МакросыC.2.1.3. ТаблицыC.2.1.4. Фильтрация пакетовC.2.1.4.1. Синтаксис правилC.2.1.4.2. ПолитикаC.2.1.4.3. Пропускаем трафикC.2.1.4.4. Ключевое слово quickC.2.1.4.5. Отслеживание состояния соединенияC.2.1.4.6. Хранение состояний для UDPC.2.1.4.7. Опции таблицы состоянийC.2.1.4.8. TCP флагиC.2.1.4.9. TCP SYN proxyC.2.1.4.10. Борьба со спуфингомC.2.1.4.11. Unicast Reverse Path ForwardingC.2.1.4.12. Пассивное детектирование операционной системыC.2.1.4.13. Опции IPC.2.1.4.14. ПримерC.2.1.5. NATC.2.1.6. Перенаправление пакетов, проброс портовC.2.1.7. Приёмы используемые для упрощения файла pf.conf(5)![[+]](images/button-green.png) C.2.2. Углублённое конфигурирование Пакетного фильтраC.2.3. Дополнительные разделыC.2.3.1. Журналирование в пакетном фильтреC.2.3.2. ПроизводительностьC.2.3.3. FTPC.2.3.4. Authpf: авторизация в пакетном фильтреC.2.3.5. CARP и pfsyncC.2.3.5.1. Введение в CARPC.2.3.5.2. Как работает CARPC.2.3.5.3. Настройка CARPC.2.3.5.4. Пример CARPC.2.3.5.5. Введение в pfsync(4)C.2.3.5.6. Использование с pfsync(4)C.2.3.5.7. Конфигурирование pfsyncC.2.3.5.8. Пример использования pfsyncC.2.3.5.9. Совместное использование CARP и
pfsync для отказоустойчивостиC.2.3.5.10. Замечания по использованию CARP и pfsyncC.2.4. Пример: брандмауэр для дома или небольшого офиса
C.2.2. Углублённое конфигурирование Пакетного фильтраC.2.3. Дополнительные разделыC.2.3.1. Журналирование в пакетном фильтреC.2.3.2. ПроизводительностьC.2.3.3. FTPC.2.3.4. Authpf: авторизация в пакетном фильтреC.2.3.5. CARP и pfsyncC.2.3.5.1. Введение в CARPC.2.3.5.2. Как работает CARPC.2.3.5.3. Настройка CARPC.2.3.5.4. Пример CARPC.2.3.5.5. Введение в pfsync(4)C.2.3.5.6. Использование с pfsync(4)C.2.3.5.7. Конфигурирование pfsyncC.2.3.5.8. Пример использования pfsyncC.2.3.5.9. Совместное использование CARP и
pfsync для отказоустойчивостиC.2.3.5.10. Замечания по использованию CARP и pfsyncC.2.4. Пример: брандмауэр для дома или небольшого офисаДанный раздел на 80% состоит из перевода официальной документации по пакетному фильтру OpenBSD. Остальные 20% — мои добавления из других источников.
Пакетный фильтр OpenBSD при запуске считывает
правила из конфигурационного файла. По умолчанию это файл
/etc/pf.conf(5). Ниже мы опишем его
синтаксис.
Списки позволяют удобным образом задать несколько похожих критериев в одном правиле. Например: вместо того, чтобы писать по одному правилу на каждый IP-адрес, который мы хотим заблокировать, мы можем использовать одно правило и передать в него список блокируемых адресов. Когда pfctl(8) встречает в конфигурационном файле список, он автоматически заменяется на несколько правил. Например:
block out on fxp0 from { 192.168.0.1, 10.5.32.6 } to any
Заменяется на
block out on fxp0 from 192.168.0.1 to any
block out on fxp0 from 10.5.32.6 to any
В одном правиле можно употреблять несколько списков:
rdr on fxp0 proto tcp from any to any port { 22 80 } -> 192.168.0.6
block out on fxp0 proto { tcp udp } from { 192.168.0.1, 10.5.32.6 } \
to any port { ssh telnet }
списки могут быть вложенными:
trusted = "{ 192.168.1.2 192.168.5.36 }"
pass in inet proto tcp from { 10.10.0.0/24 $trusted } to port 22
Будьте осторожны с отрицаниями в списках. Следующий пример демонстрирует распространённую ошибку:
pass in on fxp0 from { 10.0.0.0/8, !10.1.2.3 }
Эта запись означает не «любой адрес из сети 10.0.0.0/8 кроме 10.1.2.3», а раскрывается в следующие два правила:
pass in on fxp0 from 10.0.0.0/8
pass in on fxp0 from !10.1.2.3
Которые, фактически, означают: «пропускать все пакеты из сети 10.0.0.0/8». Для решения такой задачи лучше применять таблицы (см. Раздел C.2.1.3, «Таблицы»).
Макросы, это определённые пользователем переменные, которые
могут содержать IP-адреса, номера портов, имена интерфейсов
и т.п. Имя макроса подчиняется традиционным для
большинства языков программирования правилам: начинаться оно
должно с буквы, а за ней должны идти буквы, цифры или
символы подчерка. Имя не должно быть зарезервированным
словом, таким как pass, out или queue.
ext_if = "fxp0"
block in on $ext_if from any to any
Здесь создан макрос ext_if. Когда
надо сослаться на макрос, его имя начинают со знака $.
Макросы могут раскрываться в списки:
friends = "{ 192.168.1.1, 10.0.2.5, 192.168.43.53 }"
Макросы можно вкладывать друг в друга, но, поскольку в двойных кавычках макрос указывать нельзя, следует использовать следующий синтакс:
host1 = "192.168.1.1"
host2 = "192.168.1.2"
all_hosts = "{" $host1 $host2 "}"
Макрос $all_hosts в этом примере
будет раскрыт в список { 192.168.1.1,
192.168.1.2 }.
При помощи команды pfctl(8) можно
переопределять значения макросов с помощью опции
-D. Например:
# pfctl -D friends="{ 192.168.1.1, 10.1.2.3 }"
Таблицы используются для хранения адресов IPv4 и/или IPv6. Поиск в них осуществляется очень быстро, они расходуют значительно меньше памяти и процессорного времени, чем списки. Таблицы, таким образом, идеальны для хранения больших массивов адресов, поскольку поиск в таблице с 50 000 записей происходит не на много медленнее, чем в таблице с 50 адресами. Таблицы можно использовать следующим образом:
route-to,
reply-to,
dup-to,
Таблицы можно создавать как в конфигурационном файле
pf.conf(5), так и при помощи
управляющей утилиты pfctl(8).
В конфигуационном файле pf.conf(5)
таблицы создаются при помощи директивы table. У таблицы могут быть следующие
атрибуты:
const, persist
Пример (имя таблицы указывается в угловых скобках <...>):
table <goodguys> { 192.0.2.0/24 }
table <rfc1918> const { 192.168.0.0/16, 172.16.0.0/12, 10.0.0.0/8 }
table <spammers> persist
block in on fxp0 from { <rfc1918>, <spammers> } to any
pass in on fxp0 from <goodguys> to any
Адреса так же можно употреблять с отрицательным знаком (!), или с ключевым словом not:
table <goodguys> { 192.0.2.0/24, !192.0.2.5 }
Таблица <goodguys>, таким
образом, включает в себя всю сеть 192.0.2.0/24 кроме адреса
192.0.2.5.
Содержимое таблицы можно брать из файла:
table <spammers> persist file "/etc/spammers"
block in on fxp0 from <spammers> to any
Файл /etc/spammers должен содержать
IP-адреса и/или блоки сетей в формате CIDR по одному на
строку. Строки начинающиеся с #
считаются комментарием и игнорируются.
Таблицей можно манипулировать при помощи утилиты
pfctl(8). Например, следующая команда
добавляет в таблицу <spammers> ещё одну сеть:
# pfctl -t spammers -T add 218.70.0.0/16
Кроме того, указанная команда создаст таблицу <spammers>, если её ещё нет.
Чтобы перечислить все вхождения в таблицу можно
использовать следующую команду:
# pfctl -t spammers -T show
Опция -v может использваться вместе с
-Tshow для того, чтобы увидеть статистику
по каждому пункту в таблице:
# pfctl -t crackers -Ts -v
222.122.26.172
Cleared: Sun Jan 21 18:45:49 2007
In/Block: [ Packets: 0 Bytes: 0 ]
In/Pass: [ Packets: 0 Bytes: 0 ]
Out/Block: [ Packets: 0 Bytes: 0 ]
Out/Pass: [ Packets: 0 Bytes: 0 ]
222.175.172.2
Cleared: Sun Jan 21 18:45:49 2007
In/Block: [ Packets: 0 Bytes: 0 ]
In/Pass: [ Packets: 0 Bytes: 0 ]
Out/Block: [ Packets: 0 Bytes: 0 ]
Out/Pass: [ Packets: 0 Bytes: 0 ]
....................
Чтобы удалить адрес из таблицы можно использовать команду
# pfctl -t spammers -T delete 218.70.0.0/16
См. так же Раздел C.3, «Управление пакетным фильтром OpenBSD при помощи утилиты pfctl(8)».
Хосты в таблицах можно указывать не только в виде
IP-адреса, но так же и по имени. В этом случае имена будут
разрешены и все адреса соответствующие данному имени
попадут в таблицу. Кроме того, можно указывать имя
интерфейса или ключевое слово self. В этом случае в таблицу буду
добавлены все адреса соответствующие данному интерфейсу или
все адреса данной машины (включая кольцевой интерфейс)
соответственно.
Ограничение: адреса 0.0.0.0/0 и 0/0 в таблицах не работают. Используйте списки.
При поиске в таблице находится «наиболее подходящий» адрес, т.е. сеть с самой большой маской. (Наибольшая маска у самой «узкой» сети.) Например:
table <goodguys> { 172.16.0.0/16, !172.16.1.0/24, 172.16.1.100 }
block in on dc0 all
pass in on dc0 from <goodguys> to any
Адрес источника каждого пакета пришедшего через интерфейс
dc0 будет искаться в таблице
<goodguys>:
Фильтрация пакетов заключается в том, что пакеты пропускаются или отбрасываются при прохождении через сетевой интерфейс в соответствии с правилами. Правила основаны на заголовках пакетов сетевого и транспортного уровней модели OSI (см. OSI). Наиболее часто используемые критерии — адреса источника и назначения, номера портов источника и назначения, протоколы.
Правила фильтра состоят из критерия и действия, которое надо
предпринять, если пакет соответствует критерию. Действие
может быть или block или pass. Правила применяются по очереди
от первого к последнему, при этом последнее
правило выигрывает если только не встретится
ключеве слово quick. Таким
образом, если в самом начале конфигурационного файла задано
правило «пропускать все пакеты», или
«отбрасывать все пакеты», то это ни что иное, как
политика по умолчанию — именно это правило будет
применено к пакету, который не соответствует ни одному
правилу ниже по ходу файла.
Ниже приведена упрощённая синтаксическая схема:
action [direction] [log] [quick] [on interface] [af] [proto protocol] \
[from src_addr [port src_port]] [to dst_addr [port dst_port]] \
[flags tcp_flags] [state]
actionpass, либо block. Действие pass приводит к тому, что пакет
возвращается в ядро и направляется на другие правила.
Действие block приводит к
тому, что срабатывают настройки из политики block-policy (см. Раздел C.2.2.1, «Опции в пакетном фильтре», или настройки
определённые при помощи опций
if-bound). (Назначение данной
политики состоит в том, чтобы просто отбросить пакет,
или выслать назад какой-нибудь пакет: TCP с флагом reset
или ICMP Unreachable.) Политика может быть
переопределена в правиле: block
drop или block
return.
directionin или out.
logkeep state, modulate state или synproxy state —
в журнал попадают только пакеты открывшие соединение.
Если надо, чтобы в журнал попали вообще все пакеты,
применяйте правило log (all).
quickquick, то данное правило
считается последним и к пакету немедленно применяется
действие action. (Т.е. если у
всех правил будет высталена опция quick, то мы будем иметь дело с
брандмауэром в котором первое правило выигрывает.)
interfaceИмя сетевого интерфейса, через который проходит пакет, или имя группы сетевых интерфейсов. Группы можно создавать при помощи команды ifconfig(8) (только в OpenBSD). Кроме того, некоторые группы создаются ядром автоматически:
egress, который
содержит все интерфейсы, через которые проходят
маршруты по умолчанию.
ppp или carp).
afinet для адресов IPv4 и inet6 для адресов IPv6. Обычно
пакетный фильтр может определить требуемый протокол по
указанным в правиле адресам.
protocolПротокол транспортного уровня. Возможные варианты:
tcpudpicmp/etc/protocols.
src_addr, dst_addrАдрес источника или назначения пакета. Возможные варианты:
/netmask (например /24). Ко всем адресам
закреплённым за данным интерфейсом, будет добавлена
данная сетевая маска, и полученные сети CIDR будут
добавлены в данное правило.
(...).
Данное правило будет автоматически меняться при
смене адреса закреплённого за интерфейсом. Это
полезно для DHCP клиентов.
Имя сетевого интерфеса, за которым идёт один из следующих модификаторов:
:network:broadcast:peer
Кроме того, за именем интерфейса или за любым из
перечисленных выше модификаторов, может
следовать модификатор :0, указывающий на то,
что нас не интересуют алиасы, т.е.
дополнительные адреса, котрые можно добавить к
сетевому интерфейсу (см. Раздел 6.15, «Знание как и когда устанавливать или удалять алиасы сетевого интерфейса»). Например: fxp0:network:0.
!.
any,
означающее все адреса.
all,
которое является эквивалентом конструкции from any to any.
src_port, dst_port
Порт источника или назначения в заголовке транспортного уровня. Возможны следующие варианты:
/etc/services.
Диапазоны портов с применением следующих операторов:
!=<><=>=><<>:
Последние три оператора бинарные (принимают
два аргумента). При этом <> и >< не включают
аргументы в диапазон, а : включает.
tcp_flagsproto tcp. Флаги задаются
как flags check/mask.
mask — список
проверяемых флагов, check — список
флагов, которые должны быть включены. Например
директива flags S/SA
означает, что мы ищем пакет у которого выключен флаг
ACK, и включён флаг SYN, а остальные флаги нас не
интересуют.
state
Указывает сохраняется ли данным правилом информация о состоянии соединения. Возможные варианты:
keep statemodulate statesynproxy statekeep state и modulate state.
Полная синтаксическая схема приведена в справочной странице
man(1) по
pf.conf(5). В неё входят не упомянутые
здесь опции. Если вы только изучаете пакетный фильтр,
возможно вам стоит пропустить дальнейший список и перейти к
разделу Раздел C.2.1.4.2, «Политика», или
просто кратко ознакомиться с возможностями фильтра.
![[Внимание]](images/warning.png) | Внимание |
|---|---|
В разных системах BSD присутствуют разные
версии пакетного фильтра и не все возможности описанные
здесь могут быть реализованы в вашей системе. Больше того,
не все возможности описанные в вашем
man по pf.conf(5)
реализованы в вашей системе, так как при портировании
man, увы, не редактируют.
|
![[Замечание]](images/note.png) | Замечание |
|---|---|
Имейте в виду, что данный ниже список носит ознакомительный
характер и перед применением вам следует справиться о
синтаксисе в вашей странице man по
pf.conf(5) |
user <user><user>.
group <group>;icmp-type <type> code <code>icmp6-type <type> code <code>tos <string|number>
Правило соответствует пакетам с указанным значением
TOS. Возможные варианты: lowdelay, throughput, reliability или десятичное или
шестнадцатеричное значение. Например, следующие строки
эквивалентны:
pass all tos lowdelay
pass all tos 0x10
pass all tos 16
allow-optslabel <string>
Правило метится при помощи метки <string>. Просмотреть
статистику по помеченным правилам можно при помощи
команды pfctl(8) с опцией
-s label. Метки можно использовать для
предотвращения оптимизации, что важно при написании
биллинговой системы.
При объявлении меток можно использовать следующие макросы:
$if$srcaddr$dstaddr$srcport$dstport$proto$nrНапример:
ips = "{ 1.2.3.4, 1.2.3.5 }"
pass in proto tcp from any to $ips \
port > 1023 label "$dstaddr:$dstport"
эквивалентно
pass in proto tcp from any to 1.2.3.4 \
port > 1023 label "1.2.3.4:>1023"
pass in proto tcp from any to 1.2.3.5 \
port > 1023 label "1.2.3.5:>1023"
queue <queue> | (<queue>, <queue>)tag <string>tagged <string>fastrouteroute-to <interface> [nexthop]reply-to <interface> [nexthop]dup-to <interface> [nexthop]route-to. Оригинальный пакет
маршрутизируется обычным образом.
rtable <number>probability <num>Вероятность срабатывания правила. Задаётся как дробь от 0 до 1 или в процентах. Например, следующее правило отбрасывает пакеты ICMP с вероятностью 20%:
block in proto icmp probability 20%
Рекомендуемая практика при написании брандмауэров — делать политику «default deny», т.е. по умолчанию отбрасывать все пакеты, а потом пропускать некоторые разрешённые пакеты. Для создания политики «default deny» надо сделать следующие первые два правила:
block in all
block out all
Эти правила блокируют весь трафик на всех интерфейсах вне зависимости от направления.
Теперь нам надо явно разрешить прохождение трафика, чтобы он не был заблокирован политикой. Здесь понадобятся такие критерии как номера портов источника и назначения, адреса источника и назначения, протоколы. Правила должны быть настолько строгими, насколько это возможно, для того, чтобы через брандмауэр проходил только нужный трафик.
Например:
# Пропускать трафик из локальной сети (192.168.0.0/24) идущий через
# интерфейс dc0 на машину OpenBSD (FreeBSD, NetBSD) с адресом 192.168.0.1,
# а так же выпускать ответный трафик.
pass in on dc0 from 192.168.0.0/24 to 192.168.0.1
pass out on dc0 from 192.168.0.1 to 192.168.0.0/24
# Пропускать TCP трафик на интерфейсе fxp0 направленный на web сервер
# запущенный на нашей OpenBSD (FreeBSD, NetBSD) машине. Имя интерфейса
# использовано в качестве адреса назначения, поэтому правилу
# соответствуют только пакеты направленные к нам.
pass in on fxp0 proto tcp from any to fxp0 port www
Как было замечено выше, пакеты проходят через все правила
от начала до конца. Пакет, который пометился правилом как
проходящий (pass) может
многократно сменить действие с pass на block и обратно, в процессе
прохождения через правила. Последнее правило
выигрывает, если только пакет не встретит
правило с ключевым словом quick, которое останавливает
прохождение пакета по правилам.
Вот пара примеров:
Неправильный пример:
block in on fxp0 proto tcp from any to any port ssh
pass in all
В этом случае правило block
возможно применяется к пакетам ssh, но в итоге никогда не
срабатывает, так как дальше идёт правило, которое
разрешает весь трафик.
Правильный пример:
block in quick on fxp0 proto tcp from any to any port ssh
pass in all
В данном примере трафик ssh будет отброшен немедленно,
так как встретилось ключевое слово quick, и все другие правила
относящиеся к трафику ssh будут проигноророваны.
Неоднозначный пример:
pass in all
block in on fxp0 proto tcp from any to any port ssh
Такие два правила возможно приведут к блокированию трафика, а может быть и нет. В зависимости от того, какие правила окажутся ниже по тексту.
Одна из важных возможностей пакетного фильтра — отслеживание состояния соединений («stateful inspection»). Stateful inspection возможна благодаря возможности пакетного фильтра отслеживать состояния сетевых соединений. Состояние каждого соединения хранится в таблице состояний. Пакетный фильтр может быстро определить принадлежит ли пакет уже открытому соединению. Если пакет принадлежит уже открытому соединению, то его пропускают, не направляя на другие фильтрующие правила.
Использование таблицы состояний имеет много преимуществ: от упрощения правил фильтрации, до увеличения производительности брандмауэра. Пакетный фильтр может определить принадлежность пакета открытому соединению независимо от направления в котором идёт пакет. Это освобождает от необходимости написания правил пропускающих ответный трафик. А поскольку пакет не направляется ни на какие правила, время прохождения пакета через брандмауэр существенно уменьшается.
Если в правиле присутсвует опция keep state, первый пакет
соответствующий правилу создаёт запись в таблице состояний
связывающую источник и получателя пакета. Теперь не только
пакеты идущие от источника к получателю, но и обратные
пакеты будут соответствовать созданной записи в таблице
состояний и не будут подвергаться проверке. Например:
pass out on fxp0 proto tcp from any to any keep state
Это правило разрешает любой исходящий трафик на
интерфейсе fxp0, а так же
разрешает прохождение всего ответного трафика через
брандмауэр. Функция keep state замечательна так же
тем, что значительно улучшает производительность
брандмауэра, так как поиск в таблице состояний намного
быстрее чем проверка пакета при помощи правил фильтрации.
Функция modulate state
работает так же как keep state, но применима
только к пакетам TCP. При использовании modulate state, начальный
номер последовательности (ISN) исходящих соединений
выбирается случайным образом. Это полезно для защиты
соединений инициализированных операционными системами,
проделывающими более слабую работу по выбору номера ISN.
Начиная с OpenBSD 3.5 правило
modulate state можно
употреблять не только для протокола TCP (рандомизация
последовательности при этом будет работать для TCP
протокола, а для UDP и ICMP будет работать keep state).
Сохранять состояние TCP, UDP и ICMP трафика, и рандомизировать ISN в TCP:
pass out on fxp0 proto { tcp, udp, icmp } from any to any modulate state
Другое преимущество таблицы состояний состоит в том, что
трафик ICMP соответствующий открытому соединению тоже
пропускается через брандмауэр. Например: если keep state указан для
соединения TCP, и получено сообщение ICMP source-quench
относящееся к данному соединению TCP, то оно будет
пропущено через брандмауэр (ICMP пакет source-quench
уменьшает скорость отправки пакетов через маршрутизатор и
отсылается маршрутизатором или конечным хостом если,
например, у них переполнен буфер).
Область действия записи в таблице состояния ограничивается
задаваемой глобально опцией state-policy (см. Раздел C.2.2.1, «Опции в пакетном фильтре», или при помощи опций
if-bound), group-bound и floating, задаваемых непосредственно
в правилах. Они имеют то же значение, что и заданные
глобально политики state-policy.
Пример:
pass out on fxp0 proto { tcp, udp, icmp } from any \
to any modulate state (if-bound)
Это правило гласит, что пакет будет соответствовать записи в
таблице состояний только если он идёт через интерфейс fxp0.
Правила nat, binat и rdr тоже создают записи в
таблице состояний.
Кто-то может подумать, что для протокола UDP нельзя делать
записи в таблице состояний, так как это
«stateless» протокол. Однако пакетный фильтр
может отслеживать его состояния. Несмотря на отсутствие
«стартового» пакета, пакетный фильтр следит за
пакетами на основании таймаутов и номеров портов источника и
назначения. По достижении таймаута таблица состояний
очищается от соответствующей записи. Величину таймаута можно
задать в разделе «опции»
pf.conf, см. Раздел C.2.2.1, «Опции в пакетном фильтре»
Можно использовать некоторые опции для управления поведением
записей в таблице состояний, созданных при помощи команд
keep state, modulate state или synproxy state. Вот список этих
опций:
max numbersource-trackЭта опция даёт возможность отслеживать количество записей в таблице состояний в пересчёте на каждый адрес источника. Возможные форматы опции:
source-track rule —
Максимальное количество записей в таблице
состояний созданных данным правилом ограничивается
опциями max-src-nodes и
max-src-states,
заданными в этом правиле. Счётчики заводятся не
глобальные, а локальные.
source-track global —
То же что и в предыдущем слуаче, но счётчики
ведутся глобально. При этом каждое правило может
иметь свои пределы max-src-nodes и max-src-states, однако
счётчики будут общими для всех правил.
Общее количество адресов источников, для которых
осуществляется глобальный контроль количества строк
в таблице состояний, ограничивается при помощи опции
src-nodes. (См. Раздел C.2.2.1, «Опции в пакетном фильтре»)
max-src-nodes numbersource-track опция max-src-nodes ограничивает
количество IP-адресов с которых можно одновременно
открыть соединения.
max-src-states numbersource-track опция max-src-states ограничивает
количество соединений с одного IP-адреса.
Например:
pass in on $ext_if proto tcp to $web_server \
port www flags S/SA keep state \
(max 200, source-track rule, max-src-nodes 100, max-src-states 3)
Это правило означает следующее:
Отдельные ограничения можно ввести для TCP соединений прошедших тройное рукопожатие (см. Раздел B.1.4.3.2, «Открытие соединения TCP, тройное рукопожатие»):
max-src-conn numbermax-src-conn-rate number / interval
Обе опции автоматически включают опцию state-track rule и не совместимы с
state-track global.
В комбинации с данными опциями можно употреблять более агрессивные опции, для «наказания» «провинившихся».
overload <table>flash [global]global
записи в таблице состояний сбрасываются независимо от
того, какое правило её создало.
Пример:
table <abusive_hosts> persist
block in quick from <abusive_hosts>
pass in on $ext_if proto tcp to $web_server \
port www flags S/SA keep state \
(max-src-conn 100, max-src-conn-rate 15/5, overload <abusive_hosts> flush)
Эти правила делают следующее:
block).
При открытии соединения TCP пакетный фильтр должен изучить
флаги TCP выставленные в заголовке пакета. Описание флагов
дано в Таблица B.3, «Флаги TCP». Для изучения флагов
применяется ключевое слово flags check/mask. mask указывает фильтру, что он
изучает только указанные в этом поле флаги, а поле check указывает какие флаги должны
быть включены, чтобы удовлетворять данному правилу.
pass in on fxp0 proto tcp from any to any port ssh flags S/SA
Приведённое правило пропускает весь TCP трафик c установленным флагом SYN, при этом изучаются флаги SYN и ACK. Пакет с флагами SYN и ECE будет пропущен данным правилом, а пакет в котором выставлены флаги SYN и ACK или просто ACK не будет пропущен.
| Замечание |
|---|---|
В старых версиях поддерживался синтаксис ... flags S, в новых
версиях фильтра маска всегда должна указываться.
|
Часто флаги указываются вместе с правилом keep state для создания записи
в таблице состояний:
pass out on fxp0 proto tcp all flags S/SA keep state
Данное правило разрешает исходящие соединения начинающиеся с пакета в котором выставленн флаг SYN, а флага ACK нет.
Будьте внимательны при использовании флагов. Понимайте что вы делаете и зачем, особенно когда пользуетесь чьими-то советами. Некоторые люди предлагают открывать соединения если указан флаг SYN и никакой другой:
. . . flags S/FSRPAUEW плохоя идея!!
Теоретически первый пакет должен содержать флаг SYN и никакой другой, однако некоторые хосты выставляют флаг ECN и будут отвергнуты данным правилом. Более разумным будет следующее правило:
. . . flags S/SAFR
Это практично и безопасно, однако в этом нет необходимости, если трафик был нормализован при помощи scrub. Процесс нормализации трафика заставляет пакетный фильтр отбрасывать пакеты с неправильными сочетаниями флагов (вроде SYN+RST) или подозрительным счетанием (SYN+FIN). Крайне желательно всегда подвергать трафик нормализации:
scrub in on fxp0
.
.
.
pass in on fxp0 proto tcp from any to any port ssh flags S/SA keep state
В обычной ситуации клиент выполняет тройное рукопожатие с сервером (см. Раздел B.1.4.3.2, «Открытие соединения TCP, тройное рукопожатие»). Пакетный фильтр умеет выполнять в этой процедуре функцию посредника. При этом фильтр выполняет тройное рукопожатие с клиентом, затем проводит рукопожатие с сервером, и уже после этого начинает пробрасывать пакеты между клиентом и сервером. Этот метод позволяет избежать TCP SYN флуда (разновидность сетевой DOS атаки, когда клиент забрасывает сервер заявками на открытие соединения, но соединение не открывает. В результате у сервера могут исчерпаться сокеты. см. так же DOS атака).
Проксирование рукопожатия проводится при помощи ключевого
слова synproxy state:
pass in on $ext_if proto tcp from any to $web_server port www \
flags S/SA synproxy state
В этом примере проксируется входящее соединение к web-серверу.
synproxy state включает в
себя функционал keep state
и modulate state.
| Замечание |
|---|---|
| SYN proxy невозможен, если пакетный фильтр работает на мосту. (См. bridge.) |
IP-спуфинг — подделка исходящих адресов в заголовке IP пакета (см. spoofing).
Пакетный фильтр может осуществлять защиту от спуфинга при
помощи правил начинающихся с ключевого слова antispoof:
antispoof [log] [quick] for interface [af]
logquickinterfaceafinet и inet6.
Пример:
antispoof for fxp0 inet
Каждое правило antispoof
превращается в два правила фильтра. Например, если за
интерфейсом fxp0 закреплён адрес 10.0.0.1 и сетевая маска
255.255.255.0 (т.е. /24), то предыдущее правило
превратится в следующие два правила:
block in on ! fxp0 inet from 10.0.0.0/24 to any
block in inet from 10.0.0.1 to any
Эти правила означают следующее:
| Замечание |
|---|---|
Правило
set skip on lo0
antispoof for fxp0 inet
|
| Замечание |
|---|---|
Использование правила
block drop in on ! fxp0 inet all
block drop in inet all
и может заблокировать весь входящий трафик на всех интерфейсах. |
Начиная с OpenBSD 4.0 в пакетном фильтре появилась возможность проверять исходящие адреса при помощи таблицы маршрутизации. Если пакет подвергается проверке uRPF, исходящий IP адрес разыскивается в таблице маршрутизации, и если указанный в ней интерфейс соответствует интерфейсу, через который пришёл пакет, то пакет проходит проверку, а если нет — то мы имеем дело с IP-спуфингом.
Проверка uRPF осуществляется при помощи ключевого слова
urpf-failed:
block in quick from urpf-failed label uRPF
Проверка uRPF работает только при симметричной маршрутизации. В противном случае трафик будет заблокирован.
Если машина является конечной точкой IPSec туннеля, нельзя
включать проверку uRPF на интерфейсе enc0, иначе будет
заблокирован весь инкапсулированный трафик. Рекомендуется
пропускать все пакеты на интерфейсе enc0: set skip on enc0 или
делать так:
block in quick on ! enc0 from urpf-failed label uRPF
| Замечание |
|---|---|
| В FreeBSD uRPF пока не портирован. |
| Замечание |
|---|---|
| В FreeBSD интерфейс аналогичный упомянутому здесь интерфейсу OpenBSD enc0 будет называться gif0. |
Пакетный фильтр обладает возможностью определять из какой
операционной системы был отправлен SYN пакет. Делается это
на основе некоторых характерных особенностей работы TCP
стека разных систем. Так, извстно, что операционные
системы Windows NT склонны
выставлять поле TTL в 128, тогда как
Linux,
FreeBSD — 64. Особенности
работы стека приведены в файле
/etc/pf.os. Это обычный текстовый файл,
формат которого описан в нём же в комментариях. Текущий
список fingerprint'ов можно увидеть при помощи команды
# pfctl -s osfp
Class Version Subtype(subversion)
----- ------- -------------------
AIX
AIX 4.3
AIX 4.3 2
AIX 4.3 2-3
AIX 4.3 3
AIX 5.1
AIX 5.1-5.2
AIX 5.2
AIX 5.3
AIX 5.3 ML1
.......
В моей системе насчитывается 330 fingerprint'ов. Включая Zaurus (наладонник фирмы Sharp с Linux'ом) 2-х версий.
Фильтрацию можно осуществлять при помощи ключевого слова
os:
pass in on $ext_if from any os OpenBSD keep state
block in on $ext_if from any os "Windows 2000"
block in on $ext_if from any os "Linux 2.4 ts"
block in on $ext_if from any os unknown
Ключевое слово unknown означает
пакет от системы чьи характеристики пакетному фильтру
неизвестены.
| Замечание |
|---|---|
|
По умолчанию пакетный фильтр отбрасывает IP пакеты с
выставленными опциями, для затруднения работы программ
пытающихся узнать тип нашей операционной системы, например
nmap(1). Если у вас есть приложения
нуждающиеся в прохождении такого трафика, например
multicast или IGMP, используйте опцию allow-opts:
pass in quick on fxp0 all allow-opts
Ниже приведён краткий пример конфигурационного файла для брандмауэра между небольшой внутренней сетью и Интернетом. Здесь приведены только правила фильтрации, nat, rdr, queue опущены.
ext_if = "fxp0"
int_if = "dc0"
lan_net = "192.168.0.0/24"
# Таблица содержит все IP адреса принадлежащие брандмауэру
table <firewall> const { self }
# Не фильтруем пакеты на кольцевом интерфейсе
set skip on lo0
# Нормализуем входящий трафик
scrub in all
# Политика по умолчанию
block all
# Включаем защиту от спуфинга на внутреннем интерфейсе
antispoof quick for $int_if inet
# Разрешаем ssh соединения из локальной сети только с доверенного
# компьютера 192.168.0.15. Использование "block return" приведёт тому,
# что будет возвращаться пакет TCP RST для того, чтобы заблокированное
# соединение закрывалось правильным образом. "quick" используется для
# того, чтобы идущие ниже правила pass не переопределили данное
# действие.
block return in quick on $int_if proto tcp from ! 192.168.0.15 \
to $int_if port ssh flags S/SA
# Разрешить весь трафик из локальной сети к брандмауэру и обратно
pass in on $int_if from $lan_net to any
pass out on $int_if from any to $lan_net
# Пропустить исходящие tcp, udp и icmp пакеты на внешнем интерфейсе.
# Сохранять состояния соединений.
pass out on $ext_if proto tcp all modulate state flags S/SA
pass out on $ext_if proto { udp, icmp } all keep state
# Разрешить сединения ssh на внешнем интерфейсе если они направлены не
# брандмауэру, а другой машине (во внутренней сети). Первый пакет
# заносить в журнал, чтобы потом можно было сказать кто решил открыть
# соединение. Использовать syn proxy для защиты от syn флуда.
pass in log on $ext_if proto tcp from any to ! <firewall> \
port ssh flags S/SA synproxy state
Суть трансляции адресов NAT описана в глоссарии: NAT.
Когда клиент из внутренней сети пытается послать IP пакет в Интернет в этом пакете подменяется исходящий IP адрес на адрес шлюза, а так же, при необходимости, подменяется номер порта источника у пакетов TCP и UDP. Делается запись в таблице состояний.
Обратные пакеты находятся в таблице состояний и с ними проделывается аналогичное обратное преобразование.
Ни внутренняя машина, ни внешняя не знают о существовании NAT. Всё происходит прозрачно. Для внутренней машины NAT это просто шлюз, а внешняя машина ничего не знает о внутренней и считает, что соединение открыто шлюзом. Обнаружить NAT можно только по косвенным признакам.
Пакеты подвергаемые трансляции проходят через фильтр и
будут отброшены или пропущены в зависимости от правил
которые там встретятся. Единственное
исключение — если в правиле NAT встретится
ключевое слово pass, то в этом
случае пакет не будет подвергнут фильтрации.
Трансляция осуществляется до фильтрации. Правила фильтра увидят уже оттранслированные пакеты.
Поскольку NAT всегда используется на шлюзах и
маршрутизаторах, необходимо включить проброс пакетов. Для
этого надо выставить переменную ядра net.inet.ip.forwarding в истину.
Для этого во всех системах BSD
используется программа sysctl(8)
#sysctl -w net.inet.ip.forwarding=1#sysctl -w net.inet6.ip6.forwarding=1 <==(если исппользуется IPv6)
Чтобы сделать эти изменения постоянными следует
добавить в файл /etc/sysctl.conf
такие строки:
net.inet.ip.forwarding=1
net.inet6.ip6.forwarding=1
Синтаксическая диаграмма правила NAT в
pf.conf(5) выглядит следующим
образом:
nat [pass [log]] on interface [af] from src_addr [port src_port] to \
dst_addr [port dst_port] -> ext_addr [pool_type] [static-port]
natpasslogpass, пакеты заносятся в журнал
при помощи pflogd(8). В норме в
журнал попадает только первый пакет, при необходимости
журналировать все пакеты используйте log (all).
interfaceafinet для адресов IPv4 и inet6 для адресов IPv6. Обычно
пакетный фильтр может определить требуемый протокол по
указанным в правиле адресам.
src_addr, dst_addrАдрес источника или назначения пакета. Возможные варианты:
/netmask (например /24). Ко всем адресам
закреплённым за данным интерфейсом, будет
добавлена данная сетевая маска, и полученные сети
CIDR будут добавлены в данное правило.
(...).
Данное правило будет автоматически меняться при
смене адреса закреплённого за интерфейсом. Это
может быть полезно, например, для DHCP клиентов.
Имя сетевого интерфеса, за которым идёт один из следующих модификаторов:
:network:broadcast:peer
Кроме того, за именем интерфейса или за любым из
перечисленных выше модификаторов, может
следовать модификатор :0, указывающий на то,
что нас не интересуют алиасы, т.е.
дополнительные адреса, котрые можно добавить к
сетевому интерфейсу (см. Раздел 6.15, «Знание как и когда устанавливать или удалять алиасы сетевого интерфейса»). Например: fxp0:network:0.
!.
any,
означающее все адреса.
all,
которое является эквивалентом конструкции from any to any.
src_port, dst_port
Порт источника или назначения в заголовке транспортного уровня. Возможны следующие варианты:
/etc/services.
Диапазоны портов с применением следующих операторов:
!=<><=>=><<>:
Последние три оператора бинарные (принимают
два аргумента). При этом <> и >< не включают
аргументы в диапазон, а : включает.
ext_addrsrc_addr и dst_addr, кроме таблиц,
отрицаний с помощью ! и
ключевого слова any. Нельзя
использовать модификатор :broadcast.
pool_typestatic-portВ большинстве случаев для NAT трансляции годится примерно такая строка:
nat on tl0 from 192.168.1.0/24 to any -> 24.5.0.5
Это правило указывает, что надо осуществить NAT трансляцию на интерфейсе tl0 для каждого пакета пришедшего из сети 192.168.1.0/24 подменив адрес источника на 24.5.0.5.
Предыдущая строка корректна, но рекомендуется для облегчения поддержки брандмауэра использовать другую форму записи (в примере dc0 внутренний интерфейс, а tl0 внешний):
nat on tl0 from dc0:network to any -> tl0
При использовании имени интерфейса, как указано выше,
адрес будет определён и подставлен когда
pf.conf загружается, но не на лету.
Это может вызвать проблемы, если адрес интерфейсу
присваивается по DHCP и меняется во время работы. Чтобы
избежать этой проблемы надо указывать адрес интерфейса в
круглых скобках.
nat on tl0 from dc0:network to any -> (tl0)
Трансляция работает как для IPv4 так и для IPv6.
Соответствия между двумя хостами 1:1 можно достичь при
помощи правила binat. Это
правило ставит в соответствие один IP адрес другому. Это
можно использовать, например, для того, чтобы предоставить
доступ к web-серверу во внутренней сети по внешнему
IP-адресу. Соединения из Интернета к внешнему адресу шлюза
будут перенаправлены на внутренний web-сервер, а
соединения от сервера (например DNS запросы) будут
превращены в запросы шлюза. binat никогда не меняет номера
портов TCP и UDP.
Пример:
web_serv_int = "192.168.1.100"
web_serv_ext = "24.5.0.6"
binat on tl0 from $web_serv_int to any -> $web_serv_ext
Можно сделать исключения из трансляции при помощи
ключевого слова no. Например,
правила NAT трансляции из примера выше можно изменить
следующим образом:
no nat on tl0 from 192.168.1.208 to any
nat on tl0 from 192.168.1.0/24 to any -> 24.2.74.79
Вся сеть 192.168.1.0/24 будет транслироваться к адресу 24.2.74.79, кроме пакетов идущих от хоста 192.168.1.208.
Здесь первое правило выигрывает. Если
есть ключевое слово no
трансляция не производится. Ключевое слово no можно употреблять с правилами
binat и rdr.
Чтобы увидеть состояния соединений подвергаемых NAT
трансляции можно воспользоваться командой
pfctl(8) с аргументом
-s state.
# pfctl -s state
fxp0 TCP 192.168.1.35:2132 -> 24.5.0.5:53136 -> 65.42.33.245:22 TIME_WAIT:TIME_WAIT
fxp0 UDP 192.168.1.35:2491 -> 24.5.0.5:60527 -> 24.2.68.33:53 MULTIPLE:SINGLE
Этот отчёт (первая срока) означает следующее:
Если у вас работает NAT, вам доступен весь Интернет, но как быть если за шлюзом с NAT, в приватной сети находится машина доступ к которой нужен снаружи? Здесь нам поможет проброс портов. С его помощью мы можем перенаправлять входящий трафик на машину расположенную за шлюзом с NAT.
Пример:
rdr on tl0 proto tcp from any to any port 80 -> 192.168.1.20
С помощью этого правила все обращения к 80 порту будут пробрасываться на машину 192.168.1.20. (В Linux netfilter это действие называется DNAT, так как у пакета подменяется не source IP, а destination IP.)
Директива from any to any
полезна, но если вы знаете из какий сетей будут приходить
запросы, вы можете сузить правило:
rdr on tl0 proto tcp from 27.146.49.0/24 to any port 80 -> \
192.168.1.20
Таким образом, можно пробросить только некоторую подсеть. Данный подход позволяет так же пробрасывать разные подсети на разные хосты. Мы можем использовать это свойство для того, чтобы давать пользователям доступ к их компьютерам в локальной сети на основании адреса с которого они обращаются к шлюзу:
rdr on tl0 proto tcp from 27.146.49.14 to any port 80 -> \
192.168.1.20
rdr on tl0 proto tcp from 16.114.4.89 to any port 80 -> \
192.168.1.22
rdr on tl0 proto tcp from 24.2.74.178 to any port 80 -> \
192.168.1.23
Так же можно пробрасывать диапазоны портов:
rdr on tl0 proto tcp from any to any port 5000:5500 -> \ 192.168.1.20rdr on tl0 proto tcp from any to any port 5000:5500 -> \ 192.168.1.20 port 6000
rdr on tl0 proto tcp from any to any port 5000:5500 -> \ 192.168.1.20 port 7000:*

Транслированные пакеты, как и в случае с NAT, направляются на правила фильтра и могут быть как приняты, так и отброшены.
Единственное исключение: если в правиле rdr присутствует ключевое слово pass. В этом случае пакет не
направляется в фильтр. Вы можете считать, что это такой
короткий способ записать два правила, в одном из которых
осуществляется трансляция, а в другом употребляется ключевое
слово pass с keep state. Однако, если вы хотите
использовать какие-то другие возможности пакетного фильтра,
например modulate state или synproxy state, вам придётся
расписывать это подробно, т.е. rdr
pass в этом случае не подходит.
Кроме того, имейте в виду, что на фильтр пакеты посылаются после трансляции.
Рассмотрим следующий сценарий:
Правило перенаправления:
rdr on tl0 proto tcp from 192.0.2.1 to 24.65.1.13 port 80 \
-> 192.168.1.5 port 8000
Вид пакета перед трансляцией:
Вид пакета после трансляции:
Правила фильтра увидят что пакет идёт на машину 192.168.1.5 на порт 8000
Создание подобных отверстий в брандмауэре связано с уменьшением безопасности системы. Например, если у вас во внутренней сети находится web-сервер и вы пропустили на него трафик из Интернет, то злоумышленник может используя уязвимости в работе web-сервера или CGI сценария, получить доступ к web-серверу и, таким образом, проникнет в защищённую вами локальную сеть.
Снизить риск возникновения подобной ситуации можно путём построения демилитаризованной зоны DMZ (см. DMZ).
Перенаправление часто используется для предоставления доступа внешним машинам к внутреннему серверу:
server = 192.168.1.40
rdr on $ext_if proto tcp from any to $ext_if port 80 -> $server \
port 80
Однако при тестировании правил перенаправления из внутренней
сети они не работают. Дело в том, что пакеты из внутренней
сети не проходят через внешний интерфейс шлюза ($ext_if в примере) и потому не
подвергаются трансляции.
Добавление второго rdr правила не
спасает ситуацию: пакет проходит через внутренний интерфейс,
ему заменяют адрес назначения и он направляется на сервер,
однако исходящий адрес при этом не исправляется и поэтому
сервер будет овечать непосредственно клиенту минуя шлюз.
Клиент при этом ждёт ответа от шлюза, а не от сервера. Таким
образом, соединение так и не будет установлено.
И всё таки желательно из внутренней сети видеть сервер так же как он виден из внешней и так, чтобы для клиента всё было прозрачно. Существует несколько способов решения этой проблемы.
Сервер DNS можно настроить так, что он будет давать разные ответы в разные сети. Можно сделать так, чтобы локальные клиенты ходили на сервер непосредственно, без помощи шлюза. Такое решение, к тому же, снижает нагрузку на шлюз.
Можно переместить сервер в отдельную сеть (см. так же DMZ) и добавить новый сетевой интерфейс в шлюз.
Можно произвести проксирование TCP соединений при помощи
приложений из userspace. Приложение перехватывает
соединение, устанавливает соединение с сервером и далее
пробрасывает данные через себя. Простейший пример можно
сделать при помощи inetd(8) (см. Раздел 5.17.2, «Суперсервер inetd(8)»)и nc(1) (см.
Раздел 6.4.4, «telnet(1), nc(1)»). Следующая строка в
/etc/inetd.conf(5) создаёт сокет
привязанный к кольцевому интерфейсу, порт номер 5000.
Соединение пробрасывается на 80-й порт машины
192.168.1.10:
127.0.0.1:5000 stream tcp nowait nobody /usr/bin/nc nc -w 20 192.168.1.10 80
Теперь на внутреннем интерфейсе мы можем связать 80-й порт с нашим proxy-сервером:
rdr on $int_if proto tcp from $int_net to $ext_if port 80 -> \
127.0.0.1 port 5000
И наконец, в комбинации с правилом NAT можно достичь того, что трансляция адресов источника так же будет осуществляться и соединение будет устанавливаться ожидаемым образом.
rdr on $int_if proto tcp from $int_net to $ext_if port 80 -> $server
no nat on $int_if proto tcp from $int_if to $int_net
nat on $int_if proto tcp from $int_net to $server port 80 -> $int_if
Эти правила приведут к тому, что первый пакет поступивший
от клиента будет заново транслирован, когда будет
отправлен через внутренний интерфейс, при этом у него
будет подменён адрес источника на внутренний адрес шлюза.
Внутренний сервер ответит шлюзу, который вернёт адреса
обратно благодаря NAT и RDR трансляциям и пакет отправится
к клиенту. Это достаточно сложный приём. Нужна
осторожность, чтобы не применить правила NAT к другому
трафику, например к внешним соединениям (прошедшим через
другие правила rdr) или к
соединениям самого шлюза. Так же имейте ввиду, что это
преобразование приводит к тому, что TCP/IP стек видит
данные пакеты, полученные внутренним интерфейсом, как
направляющиеся внутрь сети.
Авторы документации к пакетному фильтру рекомендуют в общем случае использовать какое-нибудь из предыдущих решений вместо последнего.
Пакетный фильтр предоставляет различные способы упрощения
конфигурационного файла. Хорошим примером является
использование списков и
макросов. Вдобавок язык и грамматика
pf.conf(5) весьма гибки и позволяют в
ряде случаев опускать ключевые слова и употреблять их в разном
порядке, таким образом администратор не обязан зубрить
синтаксис файла pf.conf(5). В целом можно
сказать, что чем проще правила, тем проще осуществлять
поддержку брандмауэра.
Макросы полезны так как позволяют использовать понятные
имена вместо имён интерфейсов и адресов. Если меняется IP
адрес сервера можно просто переопределить макрос вместо
того, чтобы переписывать весь файл. Аналогичные соображения
касаются имён интерфейсов. Макросы позволяют упростить
модифицирование pf.conf(5) в случае
замены сетевой карты или при необходимости переноса одного и
того же файла с одной машины на другую.
Пример:
# define macros for each network interface
IntIF = "dc0"
ExtIF = "fxp0"
DmzIF = "fxp1"
# define our networks
IntNet = "192.168.0.0/24"
ExtAdd = "24.65.13.4"
DmzNet = "10.0.0.0/24"
Если в LAN появятся новые сети, или сети будут перенумерованы, достаточно будет поменять одну строку:
IntNet = "{ 192.168.0.0/24, 192.168.1.0/24 }"
Теперь после перезагрузки правил всё будет работать по-прежнему.
Следующие 8 строк служат для того, чтобы блокировать трафик связанный с приватными сетями, описаными в [RFC-1918], Нахождение таких пакетов в глобальной сети может вызвать проблемы.
block in quick on tl0 inet from 127.0.0.0/8 to any
block in quick on tl0 inet from 192.168.0.0/16 to any
block in quick on tl0 inet from 172.16.0.0/12 to any
block in quick on tl0 inet from 10.0.0.0/8 to any
block out quick on tl0 inet from any to 127.0.0.0/8
block out quick on tl0 inet from any to 192.168.0.0/16
block out quick on tl0 inet from any to 172.16.0.0/12
block out quick on tl0 inet from any to 10.0.0.0/8
Упростим эти правила при помощи списков:
block in quick on tl0 inet from { 127.0.0.0/8, 192.168.0.0/16, \
172.16.0.0/12, 10.0.0.0/8 } to any
block out quick on tl0 inet from any to { 127.0.0.0/8, \
192.168.0.0/16, 172.16.0.0/12, 10.0.0.0/8 }
Ещё лучше, если мы сделаем это с использованием макросов:
NoRouteIPs = "{ 127.0.0.0/8, 192.168.0.0/16, 172.16.0.0/12, \
10.0.0.0/8 }"
ExtIF = "tl0"
block in quick on $ExtIF from $NoRouteIPs to any
block out quick on $ExtIF from any to $NoRouteIPs
Заметьте, что макросы и списки упрощают файл
pf.conf, однако предыдущие строки всё
равно раскрываются в те же 8 правил.
Макросы можно использовать не только для хранения адресов, интерфейсов и портов, но вообще везде:
pre = "pass in quick on ep0 inet proto tcp from "
post = "to any port { 80, 6667 } keep state"
# David's classroom
$pre 21.14.24.80 $post
# Nick's home
$pre 24.2.74.79 $post
$pre 24.2.74.178 $post
Эти правила раскрываются в следующие:
pass in quick on ep0 inet proto tcp from 21.14.24.80 to any \
port = 80 keep state
pass in quick on ep0 inet proto tcp from 21.14.24.80 to any \
port = 6667 keep state
pass in quick on ep0 inet proto tcp from 24.2.74.79 to any \
port = 80 keep state
pass in quick on ep0 inet proto tcp from 24.2.74.79 to any \
port = 6667 keep state
pass in quick on ep0 inet proto tcp from 24.2.74.178 to any \
port = 80 keep state
pass in quick on ep0 inet proto tcp from 24.2.74.178 to any \
port = 6667 keep state
Пакетный фильтр обладает гибкой в тоже время человечной грамматикой. Нет необходимости строго помнить порядок ключевых слов и строго придерживаться какого-то определённого стиля.
Для определения политики отбрасывающей по умолчанию пакеты, следует задать два правила:
block in all
block out all
Это можно сократить до
block all
Когда направление не указано, пакетный фильтр считает, что пакеты следуют в обе стороны.
Аналогично можно не писать from any to
any и all, например:
block in on rl0 all
pass in quick log on rl0 proto tcp from any to any port 22 keep state
Можно упростить до
block in on rl0
pass in quick log on rl0 proto tcp to port 22 keep state
Первое правило блокирует все пакеты входящие через интерфейс rl0. Второе пропускает входящие пакеты, если они идут на 22-й порт.
Правила блокирующие пакеты и отсылающие пакеты TCP RST и ICMP Unreachable должны выглядеть так:
block in all
block return-rst in proto tcp all
block return-icmp in proto udp all
block out all
block return-rst out proto tcp all
block return-icmp out proto udp all
Их можно упростить до одной строки:
block return
Когда пакетный фильтр видит ключевое словоreturn, он сам догадывается на
какой протокол каким пакетом следует отвечать, а на какие
протоколы вообще не следует посылать никакого ответа при
блокировании соединений.
Порядок следования ключевых слов в большинстве случаев гибок. Например, следующее правило:
pass in log quick on rl0 proto tcp to port 22 \
flags S/SA keep state queue ssh label ssh
Можно переписать так:
pass in quick log on rl0 proto tcp to port 22 \
queue ssh keep state label ssh flags S/SA
Другие похожие варианты тоже будут работать.
Опции в pf.conf(5) устанавливаются при
помощи директивы set.
| Замечание |
|---|---|
| Начиная с OpenBSD 3.7 сменилось поведение пакетного фильтра относительно опций: раньше, если опция устанавливалась, она уже никогда не принимала своего значения по умолчанию. Теперь, опция принимает значение по умолчанию, если её удаляют из правил, а затем перезагружают правила. |
Пример задания опций в пакетном фильтре:
set timeout interval 10
set timeout frag 30
set limit { frags 5000, states 2500 }
set optimization high-latency
set block-policy return
set loginterface dc0
set fingerprints "/etc/pf.os.test"
set skip on lo0
set state-policy if-bound
set block-policy optionУстановить поведение по умолчанию для правил фильтра, когда срабатывает правило block. Возможные варианты:
drop — пакет
молча отбрасывается;
return — для
отброшенных пакетов TCP отсылается пакет TCP RST, для
прочих ICMP Unreachable.
В конкретных правилах значение опции может быть
переопределено. Умолчание —
drop
set debug optionУстановить уровень отладки для пакетного фильтра:
none — не
показывать отладочных сообщений;
urgent —
отладочные сообщения показываются для серьёзных
ошибок.
misc —
отладочные сообщения выводятся для различных ошибок
(помогает узнать состояние системы нормализации
трафика (scrub) и ошибки в работе таблицы
состояний);
loud —
Отладочные сообщения общего плана (позволяет изучать
сообщения от системы osfp).
Умолчание — urgent. Уровень
отладки можно также изменять при помощи команды
pfctl(8) (опция -x,
см. Раздел C.3, «Управление пакетным фильтром OpenBSD
при помощи утилиты pfctl(8)»).
set fingerprints file/etc/pf.os.
set limit option valueУстановить предел для различных опций:
frags —
Максимальное количество записей в пуле отвечающем за
нормализацию
трафика (scrub). По умолчанию —
100.
src-nodes —
Максимальное количество записей в пуле отвечающем за
отслеживание исходящих IP адресов. (Пул генерируется
правилами с ключевыми словами
sticky-addressи
source-track).
Умолчание — 10000.
states —
Максимальное количество вхождений в пул отвечающий за
состояние таблицы состояний соединений (Которая
заводится при помощи правил с ключевой фразой
keep state, см.
Раздел C.2.1.4, «Фильтрация пакетов»). Умолчание
10000.
Допустим синтаксис: set limit {
states 20000, frags 20000, src-nodes 2000 }
set loginterface interface
Задать интерфейс для которого пакетный фильтр собирает
статистическую информацию: количество прошедших пакетов,
количество заблокированных пакетов, сколько байт вошло,
сколько вышло. Статистику можно собирать одновременно
только на одном интерфейсе. При этом, счётчики match, bad-offset и т.п., а также
счётчики в таблице состояний, работают независимо от
этой опции. Чтобы отключить сбор статистики следует
выставить опцию в none. Значение по
умолчанию — none.
Просмотреть статистику можно при помощи команды
pfctl(8) с опцией
-s info.
См. Пример C.1, «Просмотр статистики на интерфейсе выбранном при помощи
опции loginterface»
set releset-optimization value
Это усовершенствование введено в
OpenBSD 4.1 и пока ещё нигде не
внедрено. Оптимизацию теперь можно задавать
непосредственно в pf.conf(5), а не
только как опцию pfctl(8) (см. Раздел C.3, «Управление пакетным фильтром OpenBSD
при помощи утилиты pfctl(8)», опция -o).
value может принимать следующие
значения:
nonebasicВыполняет следующую оптимизацию: 1) удаляет дублирующиеся правила; 2) удаляет правила, являющиеся подмножеством других правил; 3) объединяет несколько правил в таблицу, где это возможно; 4) пересортирует правила для лучшей производительности.
То же достигается указанием опции
-o команды
pfctl(8).
profilequick.
Того же эффекта можно добиться при помощи двух
опций -oo в программе
pfctl(8).
При оптимизации может измениться порядок правил, что
может привести к нарушению в работе биллинговой системы.
Для предотвращения оптимизации можно расставлять в
правилах метки label.
set optimization valueУстановить оптимизацию пакетного фильтра для различного поведения сети:
normal —
подходит ко всем сетям.
high-latency —
подходит для сетей работающих с большими задержками,
например через спутник.
aggressive —
агрессивно очищать таблицу состояний. Это может
существенно уменьшить требования к памяти на
загруженном брандмауэре, однако связано с риском
преждевременного разрыва соединений.
conservative —
крайне консервативный брандмауэр. Предотвращает разрыв
соединений, однако приводит к большому расходу памяти.
Умолчание —normal
set skip on interfaceset state-policy valueПоведение пакетного фильтра при использовании таблицы состояний (см. Раздел C.2.1.4, «Фильтрация пакетов»). Это поведение может быть переопределено в конкретных правилах фильтрации:
if-bound — Состояние
привязывается к конкретному интерфейсу, через который
прошёл первый пакет. Если ответ пришёл через другой
интерфейс, он не будет соответствовать данному
соединению.
group-bound — то же, но
привязано к группе интерфейсов (в
OpenBSD, но не в
FreeBSD, интерфейсы можно объединять
в группы).
floating — Записи в
таблице состояний не привязаны к интерфейсам.
Умолчание — floating
set timeout option valueЗадаёт таймауты в секундах:
intervalinterval секунд, прежде
чем запись будет удалена из
таблицы состояний. Умолчание —
10fragment30.
src.track0.
proto.modifier
Время в течение которого в таблице состояний
хранится запись о коннекте. Здесь
proto может быть
tcp, udp,
icmp или что-то (здесь
other), а
modifier указывает на состояние
коннекта. Конкретнее:
TCP:
tcp.firsttcp.openingtcp.establishedtcp.closingtcp.finwaittcp.closedUDP:
udp.firstudp.singleudp.multipleICMP:
icmp.firsticmp.error
Прочие протоколы обрабатываются как и
UDP:
other.first,
other.single,
other.multiple
set adaptive.start valueadaptive.end -
количество_записей_в_табилце_состояний) /
(adaptive.end -
adaptive.start)
set adaptive.end value
Пример: пусть в pf.conf(5)
написано:
set timeout tcp.first 120
set timeout tcp.established 86400
set timeout { adaptive.start 6000, adaptive.end 12000 }
set limit states 10000
Тогда, если количество записей в таблице сотояний
достигло 9000, то все таймауты будут уменьшены на 50%, в
частности tcp.first будет равен 30
секунд, а tcp.established 43200 секунд.
Нормализация трафика нужна для того, чтобы исключить неопределённость с тем куда направляется пакет. Кроме того, при нормализации собираются вместе фрагментированные пакеты, происходит защита операционных систем от некоторого вида атак и отбрасываются TCP пакеты с невозможным сочетанием флагов. Простейшая директива выглядит так:
scrub in all
Это приводит к нормализации всего входящего трафика на всех интерфейсах.
Одна из возможных причин для неиспользования
нормализации — использование NFS. Некоторые не
OpenBSD платформы используют странные
пакеты — фрагментированные, но с выставленным
битом «нефрагментировано», которые должны
отбрасываться пакетным фильтром при нормализации. Эту проблему
можно разрешить при использовании опции
no-df. Другая причина может состоять в том,
что некоторые многопользовательские сетевые игры блокируются
пакетным фильтром с запущенным нормализатором. Во всех
остальных случаях, кроме приведённых весьма необычных
ситуаций, нормализация трафика крайне желательна.
Синтаксис директивы scrub весьма напоминает
синтаксис правил фильтрации (см. Раздел C.2.1.4, «Фильтрация пакетов»). Как и в случае с NAT
трансляцией, первое правило выигрывает.
Перед директивой scrub можно употреблять
ключевое слово no, чтобы указанные пакеты не
нормализовались.
Scrub имеет следующие опции:
no-dfrandom-id.
random-idmin-ttl nummax-mss numfragment reassemblefragment cropfragment crop, второе —
fragment drop-ovl. В обоих случаях пакеты
не буферизируются как в случае fragment
reassemble.
fragment drop-ovlreassemble tcp
Нормализация соединений TCP на основе таблицы состояний.
При использовании данной опции нельзя указывать
направление in/out.
Осуществляется следующая нормализация:
Пример:
scrub in on fxp0 all fragment reassemble min-ttl 15 max-mss 1400
scrub in on fxp0 all no-df
scrub on fxp0 all reassemble tcp
| Замечание |
|---|---|
| Все мои попытки перевести это слово на руссий язык увенчались неудачей. Смысл при переводе полностью утрачивается, поэтому я буду употреблять слово anchor. Если что, то дословный перевод — якорь. Смысл примерно такой: якорь — это место куда подгружается поднабор правил и одновременно якорь это имя поднабора. Данный здесь текст частично основан на переводе выполненном Михаилом Сгибневым. Михаил словом «якорь» называл точку привязки правил, а поднабор правил Михаил называл «именованный поднабор правил». Я сохранил этот стиль в данном подразделе. |
Вдобавок к обычным наборам правил пакетный фильтр может использовать поднаборы. Если таблицы можно использовать для динамической смены на лету наборов IP-адресов, то поднаборы правил можно использовать для динамического переконфигурирования брандмауэра. С их помощью можно менять наборы правил фильтра, nat, binat и rdr.
Поднаборы правил можно объявлять при помощи «якорей», — anchor Существует четыре типа anchor'ов:
anchor name — выполняются все
правила фильтра из
набора name;
binat-anchor name — выполняются все
правила binat трансляции из
набора name;
nat-anchor name — выполняются все
правила nat трансляции из
набора name;
rdr-anchor name — выполняются все
правила перенаправления из
набора name;
Поднаборы могут быть вложенными и вызывать друг друга по
цепочке. Правила anchor обрабатываются в том месте, где они
вызываются. Например, правило anchor в
основном конфигурационном файле создаёт поднабор, родителем
которого являентся главный набор правил, другие поднаборы
загружаемые в данном поднаборе при помощи директивы
load anchor являются его потомками.
Именованный набор — это группа правил фильтрации, и/или правил трансляции, которым было назначено имя. Когда пакетный фильтр обнаруживает якорь в главном наборе правил, он производит проверку всех поднаборов правил привязанных к нему.
Пример:
ext_if = "fxp0"
block on $ext_if all
pass out on $ext_if all keep state
anchor goodguys
Этот набор правил устанавливает по умолчанию запретительную
политику на интерфейсе fxp0 для
всего входящего и исходящего трафика. Разрешается весь
исходящий трафик и подгружается именованный набор правил
goodguys. Якоря могут быть связаны с правилами двумя
методами:
loadЗагрузка правил указывает pfctl(8) загрузить правила из текстового файла. Например:
load anchor goodguys:ssh from "/etc/anchor-goodguys-ssh"
Когда будет загружен главный набор, правила, перечисленные в
файле /etc/anchor-goodguys-ssh будут
загружены в именованный набор ssh, ассоциированный с якорем goodguys.
Используя pfctl(8) можно добавить правило к якорю:
# echo "pass in proto tcp from 192.0.2.3 to any port 22" | pfctl -a goodguys:ssh -f -
Таким образом, мы добавляем правило pass к именованному набору ssh связанному с якорем goodguys. Пакетный фильтр будет
проверять эти правила, когда доберётся до якоря goodguys.
Правила также могут быть сохранены и загружены из текстового файла:
#cat >> /etc/anchor-goodguys-www pass in proto tcp from 192.0.2.3 to any port 80 pass in proto tcp from 192.0.2.4 to any port { 80 443 }#pfctl -a goodguys:www -f /etc/anchor-goodguys-www
Эта операция загрузит правила из файла
/etc/anchor-goodguys-www в именованый
набор правил www якоря
goodguys.
Поскольку наборы правил могут быть вложенными, существует возможность вызвать все правила вложенные в некоторый набор:
anchor "spam/*"
Синтаксис правил в подгружаемых наборах правил такой же как и в главном наборе правил, но все используемые макросы должны быть определены в пределах этого же набора: макросы, определённые в главном наборе не видны из именованного набора.
Каждый именованный набор существует обособленно от остальных. Операции, проводимые над ним, такие как сброс правил, не имеют эффекта над остальными. Кроме того, удаление указателя на якорь не приводит к удалению ни самого якоря ни привязанных к нему именованных наборов правил. Именованный набор существует до тех пор, пока все его правила не будут сброшены, используя pfctl(8). Якорь уничтожается как только не остается ни одного привязанного к нему набора правил.
Правило anchor позволяет так же
указать интерфейс, протокол, адреса источника и назначения и
прочее. Синтаксис аналогичен синтаксису правил фильтрации.
Если эта информация есть, то набор правил соответствующих
якорю используется для пакета только данные критерии
удовлетворены:
ext_if = "fxp0"
block on $ext_if all
pass out on $ext_if all keep state
anchor ssh in on $ext_if proto tcp from any to any port 22
Правила из якоря ssh будут
использоваться только если пакет был TCP и пришёл на 22-й
порт через интерфейс fxp0.
Правила к якорю могут добавляться так:
# echo "pass in from 192.0.2.10 to any" | pfctl -a ssh:allowed -f -
Несмотря на то, что в правиле не определён ни порт, ни протокол, ни интерфейс, хосту 192.0.2.10 будет разрешена работа только по протоколу ssh, в силу определений сделанных при объявлении якоря.
Управление именованными наборами правил осуществляется при помощи утилиты pfctl(8). Она позволяет удалять и добавлять правила в набор без перезагрузки главного набора правил.
Вывести список правил из набора ssh:
# pfctl -a ssh -s rules
Сбросить набор правил ssh:
# pfctl -a ssh -F rules
Поставить что-то в очередь, значит сохранить это до обработки. При работе в сети, данные получаемые хостом поступают в очередь и ждут, когда они будут обработаны операционной системой, при этом она решает, какие именно пакеты и в каком порядке обрабатывать. Изменение порядка обработки пакетов может оказать влияние на производительность сети. В идеальном случае, пакеты ssh должны обрабатываться в первую очередь, так как этот протокол очень чувствителен к задержкам. При нажатии клавиши в ssh-клиенте ожидается немедленный ответ, но идущая передача по ftp вызывает задержку в несколько секунд. Что может произойти в случае, когда роутер обрабатывает большое количество ftp пакетов? Пакеты ssh сохраняются в очереди, а то и просто отбрасываются в случае малого буфера и в результате ssh сессия может вообще прерваться. Изменение стратегии организации очередей может позволить распределить пропускную способность между различными приложениями, пользователями и хостами.
Обратите внимание, что организация очереди имеет смысл только для исходящих соединений, потому что как только пакет попал на входящий интерфейс с ним уже поздно что-либо делать, так как полоса пропускания канала была уже использована. Единственным решением этой проблемы может стать организация очереди на смежном маршрутизаторе или позволять организацию очереди на внутреннем интерфейсе, если хост сам является смежным маршрутизатором.
Планировщиком называется то, что организовывает очередь и определяет порядок обработки пакетов. По умолчанию в OpenBSD в качестве планировщика используется FIFO, очередь. Принцип её работы очень прост — первый вошёл — первый вышел. Новоприбывший пакет добавляется в конец очереди. При превышении максимального размера очереди пакет отбрасывается. Это явление известно как tail-drop (отброс хвоста, как у ящерицы).
Есть и другие планировщики. OpenBSD (и FreeBSD) поддерживает ещё три планировщика:
В очередях базирующиеся на классах (CBQ) алгоритм организации очереди построен на разделении полосы пропускания между различными очередями или классами. Трафик присоединяется к очереди на основании адреса источника или отправителя, порта, протокола и т.д. Очередь может быть сконфигурирована на заимствование произвольной полосы пропускания от родительской очереди, если та занимает свой канал не полностью. Очереди также могут работать с системой приоритетов, например, пропуская ssh трафик в первую очередь, по сравнению с трафиком ftp.
В CBQ очереди размещаются иерархическим способом. В самом верху — родительская очередь, определяющая общую пропускную способность. Дочерним очередям назначается некоторая часть от полосы пропускания родительской очереди. Например, очереди могут быть определены следующим способом:
Root Queue (2Mbps)
Queue A (1Mbps)
Queue B (500kbps)
Queue C (500kbps)
Здесь общая полоса пропускания — 2 мегабита в секунду (megabits per second — Mbps), Которая разделена на три подочереди.
| Замечание |
|---|---|
| Полосу пропускания обычно измеряют в битах в секунду. При этом 1000 bps = 1 kbps, 1000 kbps = 1 Mbps. 1 Mbps = 125000 байт в секунду или 122 килобайта в секунду. |
Иерархия может быть расширена с использованием вложенности. Для того, чтобы разделить полосу пропускания между различными пользователями, при этом сделав так, что бы различные виды трафика не мешали друг другу, можно создать следующую структуру очередей:
Root Queue (2Mbps)
UserA (1Mbps)
ssh (50kbps)
bulk (950kbps)
UserB (1Mbps)
audio (250kbps)
bulk (750kbps)
http (100kbps)
other (650kbps)
Обратите внимание, что на каждом уровне сумма полос пропускания не может быть больше родительской.
Очередь может быть настроена таким образом, что будет заимствовать (borrow) полосу пропускания у родителя в случае неиспользования ее другими очередями. Рассмотрим такую организацию очереди:
Root Queue (2Mbps)
UserA (1Mbps)
ssh (100kbps)
ftp (900kbps, borrow)
UserB (1Mbps)
Если трафик в очереди ftp превышает 900 kbps, а трафик в очереди UserA — меньше чем 1 Mbps (потому что очередь ssh использует меньше чем 100 kbps), полоса пропускания ftp может быть увеличена. Таким образом очередь ftp способна использовать больше чем назначенные ей 900 kbps, но в случае увеличения очереди ssh заимствованая полоса освобождается.
CBQ может назначать каждой группе определённый приоритет. В моменты перегрузки предпочтение отдается очередям с более высоким приоритетом в случае наличия у них одного родителя. При одинаковых приоритетах очереди обслуживаются циклически. Для примера:
Root Queue (2Mbps)
UserA (1Mbps, priority 1)
ssh (100kbps, priority 5)
ftp (900kbps, priority 3)
UserB (1Mbps, priority 1)
Очереди UserA и UserB будут обрабатываться циклически, так как их приоритеты равны. В случае перегрузки в сети, предпочтение будет отдаваться ssh, так как её приоритет больше, чем у очереди ftp. При этом очереди ssh и ftp не имеют приоритета перед очередями UserA и UserB, так как они находятся на более низком уровне.
Детальная информация о CBQ приведена в References on CBQ.
Приоритетные очереди (PRIQ) создаются на сетевом интерфейсе, причем структура очередей является плоской — нельзя создавать дочерние очереди. Сперва определяется корневая очередь с указанием общей пропускной способности, а за ней все дочерние очереди. Например:
Root Queue (2Mbps)
Queue A (priority 1)
Queue B (priority 2)
Queue C (priority 3)
Пропускная способность основной очереди определена как 2 Mbps, следом идут дочерние.
При использовании PRIQ вы должны очень тщательно планировать очереди, так как они обрабатываются строго по приоритетам и если трафик с высоким приоритетом займёт весь канал, пакеты принадлежащие трафику с низким приоритетом будут отбрасываться.
Очереди закреплённые за интерфейсом выстраиваются в иерархическое древо, каждая очередь может иметь потомка. Каждая очередь может иметь свой приоритет и свою полосу пропускания. Этот вид очереди похож на CBQ. Основное отличие HFSC от CBQ в том, что она позволяет отдельно регулировать задержки и пропускную способность очереди.
В CBQ единственный параметр очереди это полоса пропускания. Если мы нарисуем «кривую сервиса» (прохождение пакетов по времени), то это будет некоторая прямая. Единственный способ снизить задержки при работе такой очереди состоит в том, чтобы увеличить полосу пропускания.
В HFSC кривая сервиса состоит из двух линейных участков:
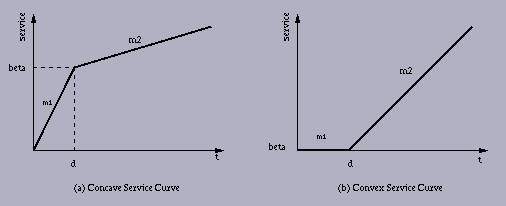
Дополнительная информация о HFSC может быть найдена по адресу http://www.cs.cmu.edu/~hzhang/HFSC/main.html.
Случайное раннее обнаружение (Random Early Detection, RED) — это алгоритм определения перегрузки канала. Его целью является предотвращение переполнения очереди. Делается это путём непрерывного сравнения текущей длины очереди с минимальным и максимальным порогами. Если минимальный порог не достигнут — все пакеты пропускаются. Если достигнут максимальные порог — все пакеты отбрасываются. В промежутке пакеты отбрасываются с определённой вероятностью, зависящей от размера очереди. Чем ближе к максимальному порогу — тем выше вероятность. Пакеты для отбрасывания выбираются случайным образом из разных сессий. Чем большая полоса пропускания занимается сессией, тем выше вероятность сброса из неё пакета.
RED весьма полезен, так как позволяет избежать ситуации, называемой «глобальной синхронизацией», она проявляется в том, что связь полностью прекращается из-за одновременно отбрасываемых пакетов с разных сессий. Например, если перегрузка происходит на маршрутизаторе, обслуживающем 10 одновременных сессий ftp и будут отброшены пакеты от большинства или всех сессий, общая пропускная способность резко понизится. RED позволяет избежать этого, выбирая сессии из которых терять пакеты случайным образом. Поскольку сессии занимающие больше полосы пропускания имеют больший шанс на потерю пакета, то возможность возникновения перегрузки исчезнет и больших потерь трафика не произойдет. Кроме того, RED позволяет обработать взрывной всплеск трафика, так как начинает отбрасывать пакеты до переполнения очереди.
RED должен использоваться только тогда, когда транспортный протокол способен реагировать на индикаторы перегрузки сети. В большинстве случаев это означает, что RED должен применяться только к очередям TCP, а не к очередям UDP или ICMP.
Детальная информация о RED приведена в References on RED.
Явное уведомление о перегрузке (ECN) работает совместно с RED и применяется для уведомления двух связанных хостов о перегрузке сети. Делается это разрешением RED установить флаг в заголовке пакета, вместо того, чтобы отбросить пакет. Если удалённый хост поддерживает ECN и читает флаги ECE и CWR, то он начинает снижать исходящий трафик (см. Таблица B.3, «Флаги TCP», [RFC-3168]).
Начиная с OpenBSD 3.0 Alternate Queueing (ALTQ) стал частью основной системы, а с версии OpenBSD 3.3 ALTQ был интегрирован в пакетный фильтр и, следовательно, портирован вместе с ним и в FreeBSD. Реализация ALTQ в OpenBSD поддерживает планировщики CBQ PRIQ и RED вместе с ECN.
Очереди конфигурируются в файле
/etc/pf.conf(5). Есть два типа
директив, которые используются для конфигурирования
очередей:
altq onqueue
Синтаксис директивы altq:
altq on interface scheduler bandwidth bw qlimit qlim \
tbrsize size queue { queue_list }
interfaceschedulercbq и priq. На интерфейсе в один момент
времени можно установить только один планировщик.
bwqlimsizequeue_listПриведённый здесь текст является моим домыслом, и не имеет отношения к оригинальной документации по пакетному фильтру:
При регулировке полосы пропускания иногда применяют концепцию токенов: есть некоторая корзина (bucket) в которую регулярно, скажем раз в секунду, кладут билет (token). Пакет идущий сквозь очередь должен взять билет из корзины и проходить. Если билета в корине нет, пакет отбрасывается, если пакеты через очередь не идут, билеты копятся в корзине, пока она не переполнится.
Таким образом, если корзина очень большая, у нас после паузы в трафике могут наблюдаться резкие всплески. Если корзина маленькая — трафик будет равномерен, но малейшие флуктуации в скорости могут привести к отбросу пакетов.
Вот этот параметр и есть, по-видимому, token bucket regulator.
Итак:
altq on fxp0 cbq bandwidth 2Mb queue { std, ssh, ftp }
Это правило запускает CBQ на интерфейсе
fxp0, пропускная способность
канала 2 Mb и создаются три дочерние очереди: std, ssh
и ftp.
Синтаксис директивы queue:
queue name [on interface] bandwidth bw [priority pri] [qlimit qlim] \
scheduler ( sched_options ) { queue_list }
namealtq
опцией queue_list. Для cbq
это также может быть запись имени очереди в предыдущей
директиве queue параметре
queue_list. Имя не должно быть
длиннее 15 символов.
interfacebwpriqlimschedulersched_options
дополнительные опции для управления планировщиками:
defaultredrioecnborrowqueue_list
Следующие три опции применяются только для очереди типа HFSC.
realtime <sc>upperlimit <sc>linkshare <sc>
Здесь <sc> это
сокращение для service curve — кривая
сервиса. Кривая состоит из двух линейных участков и
описывается тремя числами (m1, d, m2).
m1 — начальная полоса пропускания (т.е.
наклон первой кривой), d время в течении которого
действует первичная полоса пропускания в
миллисекундах и m2 — наклон второго
линейного участка — т.е. реальная полоса
пропускания.
Столь детальное описание кривой сервиса позволяет отдельно регулировать задержки при работе очереди и полосу пропускания, тогда как в CBQ есть только регулировка полосы пропускания и, следовательно, единственный способ снизить задержки состоит в увеличении полосы пропускания.
Продолжение примера:
queue std bandwidth 50% cbq(default)
queue ssh { ssh_login, ssh_bulk }
queue ssh_login priority 4 cbq(ecn)
queue ssh_bulk cbq(ecn)
queue ftp bandwidth 500Kb priority 3 cbq(borrow red)
Здесь определяются дочерние очереди. Очереди std назначается 50% пропускной способности от материнской очереди и она назначается дефолтной. Очередь ssh определяет две дочерние очереди, ssh_login и ssh_bulk. Ssh_login дают более высокий приоритет чем ssh_bulk, и обе работают с ECN. Ftp назначена полоса пропускания в 500 kbps и дан приоритет 3. Эта очередь может арендовать свободную пропускную способность других очередей и используется red.
Для направления трафика в очередь используется ключевое слово queue в правилах пакетного фильтра. Для примера рассмотрим следующую строку:
pass out on fxp0 from any to any port 22
Пакеты из этого правила можно направить в очередь следующим способом:
pass out on fxp0 from any to any port 22 queue ssh
Если ключевое слово queue
используется совместно с block,
все пакеты TCP RST или ICMP Unreachable ставятся в
указанную очередь.
Обратите внимание, что queue
может приключиться для другого интерфейса, чем было
определено директивой altq:
altq on fxp0 cbq bandwidth 2Mb queue { std, ftp }
queue std cbq(default)
queue ftp bandwidth 1.5Mb
pass in on dc0 from any to any port 21 queue ftp
Очередь определяется на fxp0, но указание на неё встречается на dc0. Если пакет, соответствующий правилу выходит с интерфейса fxp0, то он будет поставлен в очередь ftp. Этот тип очередей может быть очень полезен на маршрутизаторах.
Обычно с ключевым словом queue
используется только одно имя очереди, но если определено и
второе имя, то очередь будет использоваться для пакетов с
Type of Service (ToS) низкой задержки и для пакетов TCP ACK
без полезного груза данных. Хороший пример может быть
найден при использовании ssh: во время открытия сессии ToS
устанавливается в low-delay пока не откроется сессия SCP
или SFTP. PF может использовать информацию о находящихся в
очереди пакетах для того. чтобы отличить пакеты на ввод
логина от остальных пакетов. Возможно будет полезным
разнести по приоритетам пакеты авторизации от пакетов
данных:
pass out on fxp0 from any to any port 22 queue(ssh_bulk, ssh_login)
Повышение приоритета пакетов TCP ACK имеет смысл на асинхронных соединениях, таких как ADSL, где скорость входящего и исходящего потока не равны между собой. На ADSL линии при полностью занятом исходящем канале будет снижаться и полезное использование входящего канала, так как пакеты TCP ACK будут теряться и задерживаться. Тестирования показали, что для достижения наибольшей эффективности, полоса пропускания должна быть немного меньше, возможностей канала. Например, если ADSL линия дает максимальную скорость в 640 kbps, установите значение пропускной способности для корневой линии в 600 kb. Оптимальное значение находится путем проб и ошибок.
Когда ключевое слово queue
используется с правилами keep
state, пакетный фильтр будет делать запись
очереди в таблице состояний таким образом, что пакеты с
fxp0 соответствующие образовавшемуся соединению будут
оказываться в очереди ssh:
pass in on fxp0 proto tcp from any to any port 22 flags S/SA \
keep state queue ssh
Обратите внимание, что ключевое слово queue применяется к правилам,
обслуживающим входящий трафик.
[ Alice ] [ Charlie ]
| | ADSL
---+-----+-------+------ dc0 [ OpenBSD ] fxp0 -------- ( Internet )
|
[ Bob ]
В этом примере OpenBSD используется как шлюз в Интернет для маленькой домашней сети с тремя рабочими станциями. На шлюзе работает NAT и фильтрация пакетов. Выход в Интернет осуществляется по ADSL с входящей скоростью 2Mbps и исходящей 640Kbps.
Для очередей действуют следующие правила:
Ниже представлены правила, реализующие эту политику.
Обратите внимание, что в pf.conf не
представлены правила nat, rdr, options, и т.д.
непосредственно не имеющие отношения к данной задаче.
# Включаем очереди на внешнем интерфейсе для контроля за трафиком
# выходящим в Интернет. Используем планировщик priq для контроля только
# по приоритетам. Устанавливает ширину пропускания 610 kbps для
# оптимального пропускания очереди TCP ACK
altq on fxp0 priq bandwidth 610Kb queue { std_out, ssh_im_out, dns_out, \
tcp_ack_out }
# определяем параметры дочерних очередей
# std_out - стандартная очередь. Любые правила ниже, в которых
# очередь не указана явно, добавляют трафик к этой
# очереди.
# ssh_im_out - интерактивный SSH и интернет пейджеры
# dns_out - запросы DNS
# tcp_ack_out - пакеты TCP ACK не несущие полезной нагрузки
queue std_out priq(default)
queue ssh_im_out priority 4 priq(red)
queue dns_out priority 5
queue tcp_ack_out priority 6
# Включаем очереди на внутреннем интерфейсе для контроля трафика
# пришедшего из Интернет. Используем планировщик cbq для контроля полосы
# пропускания. Максимальная полоса 2 Mbps.
altq on dc0 cbq bandwidth 2Mb queue { std_in, ssh_im_in, dns_in, bob_in }
# определяем параметры дочерних очередей
# std_in - стандартная очередь. Любые правила ниже, в которых
# очередь не указана явно, добавляют трафик к этой
# очереди.
# ssh_im_in - интерактивный SSH и интернет пейджеры
# dns_in - ответы DNS
# bob_in - Полоса зарезервированная для Боба, разрешаем ему
# увеличивать полосу по мере возможности (borrow)
queue std_in bandwidth 1.6Mb cbq(default)
queue ssh_im_in bandwidth 200Kb priority 4
queue dns_in bandwidth 120Kb priority 5
queue bob_in bandwidth 80Kb cbq(borrow)
# ... раздел фильтрации ...
alice = "192.168.0.2"
bob = "192.168.0.3"
charlie = "192.168.0.4"
local_net = "192.168.0.0/24"
ssh_ports = "{ 22 2022 }"
im_ports = "{ 1863 5190 5222 }"
# правила фильтрации входящего трафика на fxp0
block in on fxp0 all
# правила фильтрации исходящего трафика на fxp0
block out on fxp0 all
pass out on fxp0 inet proto tcp from (fxp0) to any flags S/SA \
keep state queue(std_out, tcp_ack_out)
pass out on fxp0 inet proto { udp icmp } from (fxp0) to any keep state
pass out on fxp0 inet proto { tcp udp } from (fxp0) to any port domain \
keep state queue dns_out
pass out on fxp0 inet proto tcp from (fxp0) to any port $ssh_ports \
flags S/SA keep state queue(std_out, ssh_im_out)
pass out on fxp0 inet proto tcp from (fxp0) to any port $im_ports \
flags S/SA keep state queue(ssh_im_out, tcp_ack_out)
# правила фильтрации входящего трафика на dc0
block in on dc0 all
pass in on dc0 from $local_net
# правила фильтрации исходящего трафика на dc0
block out on dc0 all
pass out on dc0 from any to $local_net
pass out on dc0 proto { tcp udp } from any port domain to $local_net \
queue dns_in
pass out on dc0 proto tcp from any port $ssh_ports to $local_net \
queue(std_in, ssh_im_in)
pass out on dc0 proto tcp from any port $im_ports to $local_net \
queue ssh_im_in
pass out on dc0 from any to $bob queue bob_in
( IT Dept ) [ Boss's PC ]
| | T1
--+----+-----+---------- dc0 [ OpenBSD ] fxp0 -------- ( Internet )
| fxp1
[ COMP1 ] [ WWW ] /
| /
--+----------'
В этом примере OpenBSD выступает в роли системы сетевой защиты для корпоративной сети. В компании работает WWW сервер, установленный в DMZ. Клиенты обновляют свои сайты через FTP. У IT одела имеется собственная подсеть, соединённая с главной, босс использует свой компьютер для почты и серфинга по сети. Соединение с Интернетом осуществляется на скорости T1 (1.5 Mbps) в обе стороны. Все прочие сетевые сегменты используют Fast Ethernet (100 Mbps).
Сетевой администратор выбрал следующую политику:
Трафик между WWW сервером и Интернетом ограничивается 500 kbps:
Ниже представлены правила, реализующие эту политику.
Обратите внимание, что в pf.conf не
представлены правила nat, rdr, options, и т.д.
непосредственно не имеющие отношения к данной задаче.
# Включаем очереди на внешнем интерфейсе для пакетов выходящих в
# Интернет. Используем планировщик cbq чтобы контролировать полосу
# пропускания каждой очереди. Максимальная исходящая полоса 1.5 Mbps
altq on fxp0 cbq bandwidth 1.5Mb queue { std_ext, www_ext, boss_ext }
# определяем параметры дочерних очередей
# std_ext - стандартная очередь. Так е является очередью для
# исходящего трафика на интерфейсе fxp0
# www_ext - контейнер для очередей WWW сервера. Размер 500 kbps
# www_ext_http - http трафик WWW сервера - высший приоритет
# www_ext_misc - не-http трафик WWW сервера
# boss_ext - трафик пришедший с компьютера босса
queue std_ext bandwidth 500Kb cbq(default borrow)
queue www_ext bandwidth 500Kb { www_ext_http, www_ext_misc }
queue www_ext_http bandwidth 50% priority 3 cbq(red borrow)
queue www_ext_misc bandwidth 50% priority 1 cbq(borrow)
queue boss_ext bandwidth 500Kb priority 3 cbq(borrow)
# Включить очереди на внутреннем интерфейсе для контроля трафика
# входящего из интернета или из DMZ. Используем планировщик cbq для
# контроля за каждой очередью. Полоса пропускания устанавливается в
# максимум. Трафику из DMZ позволяется использовать всю полосу, а
# трафику пришедшему из Интернет рарешается использовать 1.0 Mbps
# (поскольку 0.5 Mbps (500 kbps) зарезервировано на fxp1).
altq on dc0 cbq bandwidth 100% queue { net_int, www_int }
# определяем параметры дочерних очередей
# net_int - Контейнер для трафика из Интернет. Полоса 1.0 Mbps
# std_int - Стандартная очередь. Так же является оередью по умолчанию
# для исходящего трафика на dc0
# it_int - Трафик IT-отдела. Им зарезервировано 500 kbps
# boss_int - Трафик босса имеет высший приоритет
# www_int - Трафик WWW сервера из DMZ не имеет ограничений
queue net_int bandwidth 1.0Mb { std_int, it_int, boss_int }
queue std_int bandwidth 250Kb cbq(default borrow)
queue it_int bandwidth 500Kb cbq(borrow)
queue boss_int bandwidth 250Kb priority 3 cbq(borrow)
queue www_int bandwidth 99Mb cbq(red borrow)
# Включаем очереди на интерфейсе DMZ для контроля трафика идущего к WWW
# серверу. Используем планировщик cbq для контроля за полосой
# пропускания. Полоа выставляется в максимум. Трафик из внутренней сети
# может использовать всю полосу пропускания, а трафик из Интернет
# ограничен 500 kbps.
altq on fxp1 cbq bandwidth 100% queue { internal_dmz, net_dmz }
# определяем параметры дочерних очередей
# internal_dmz - трафик из внутренней сети
# net_dmz - контейнер для очередей трафика идущего из Интернет
# net_dmz_http - http трафик, наивысший приоритет
# net_dmz_misc - не-http трафик. Это очередь по умолчанию
queue internal_dmz bandwidth 99Mb cbq(borrow)
queue net_dmz bandwidth 500Kb { net_dmz_http, net_dmz_misc }
queue net_dmz_http bandwidth 50% priority 3 cbq(red borrow)
queue net_dmz_misc bandwidth 50% priority 1 cbq(default borrow)
# ... раздел фильтрации ...
main_net = "192.168.0.0/24"
it_net = "192.168.1.0/24"
int_nets = "{ 192.168.0.0/24, 192.168.1.0/24 }"
dmz_net = "10.0.0.0/24"
boss = "192.168.0.200"
wwwserv = "10.0.0.100"
# default deny
block on { fxp0, fxp1, dc0 } all
# правила фильтрации входящего трафика на интерфейсе fxp0
pass in on fxp0 proto tcp from any to $wwwserv port { 21, \
> 49151 } flags S/SA keep state queue www_ext_misc
pass in on fxp0 proto tcp from any to $wwwserv port 80 \
flags S/SA keep state queue www_ext_http
# правила фильтрации исходящего трафика на интерфейсе fxp0
pass out on fxp0 from $int_nets to any keep state
pass out on fxp0 from $boss to any keep state queue boss_ext
# правила фильтрации входящего трафика на интерфейсе dc0
pass in on dc0 from $int_nets to any keep state
pass in on dc0 from $it_net to any queue it_int
pass in on dc0 from $boss to any queue boss_int
pass in on dc0 proto tcp from $int_nets to $wwwserv port { 21, 80, \
> 49151 } flags S/SA keep state queue www_int
# правила фильтрации исходящего трафика на интерфейсе dc0
pass out on dc0 from dc0 to $int_nets
# правила фильтрации входящего трафика на интерфейсе fxp1
pass in on fxp1 proto { tcp, udp } from $wwwserv to any port 53 \
keep state
# правила фильтрации исходящего трафика на интерфейсе fxp1
pass out on fxp1 proto tcp from any to $wwwserv port { 21, \
> 49151 } flags S/SA keep state queue net_dmz_misc
pass out on fxp1 proto tcp from any to $wwwserv port 80 \
flags S/SA keep state queue net_dmz_http
pass out on fxp1 proto tcp from $int_nets to $wwwserv port { 80, \
21, > 49151 } flags S/SA keep state queue internal_dmz
Адресным пулом называется адресное пространство более чем из
двух адресов, используемое группой пользователей. Адресный пул
может быть указан в правилах перенаправления, трансляции и
указан как адрес назначения в опциях фильтрации route-to, reply-to и dup-to.
Существует четыре способа использования адресных пулов:
bitmaskrandomsource-hashsource-hash в шестнадцатеричном
формате или как строка. По умолчанию,
pfctl(8) генерирует случайный ключ при
каждой загрузке набора правил.
round-robin
За исключением метода round-robin,
пул адресов должен быть определён как блок адресов
CIDR. В методе round-robin используется назначение
адресов из таблицы.
Опция sticky-address (дословно
«липкий адрес») может использоваться с пулами random и round-robin для гарантии назаначения
всегда одного и того же адреса источника в адрес пула.
Пул адресов можно использовать для трансляции адресов в правилах nat. Адрес источника транслируется не в отдельный адрес, а в адрес взятый при помощи одного из перечисленных выше методов из пула. Это может оказаться очень полезным в случае. когда пакетный фильтр транслирует адреса для очень большой сети. Так как число одновременных NAT соединений на один внешний адрес ограниченно, выделение для этих целей пула адресов позволит значительно увеличить число пользователей.
В следующем примере пул из двух адресов используется для трансляции исходящих пакетов. Для каждого исходящего соединения пакетный фильтр производит ротацию адресов методом round-robin:
nat on $ext_if inet from any to any -> { 192.0.2.5, 192.0.2.10 }
Существенным недостатком этого метода будет то, что не всегда будет соблюдаться соответствие между исходным адресом и адресом трансляции. Это может вызвать проблему при заходе на web-узлы: они не смогут корректно обрабатывать информацию о сессиях. Решением этой проблемы может стать использование метода source-hash для привязки внутреннего адреса к адресу трансляции. В этом случае адресный пул должен быть определён как сетевой блок CIDR:
nat on $ext_if inet from any to any -> 192.0.2.4/31 source-hash
В этом правиле nat используется пул адресов 192.0.2.4/31
(192.0.2.4 — 192.0.2.5) как адреса трансляции
для исходящих пакетов. Каждый внутренний адрес будет всегда
транслироваться в свой внешний адрес, так как указано
ключевое слово source-hash.
Пулы адресов также могут использоваться для балансировки нагрузки входящих подключений. Для примера, входящие подключения на web-сервер могут быть распределены между серверной фермой:
web_servers = "{ 10.0.0.10, 10.0.0.11, 10.0.0.13 }"
rdr on $ext_if proto tcp from any to any port 80 -> $web_servers \
round-robin sticky-address
Все соединения циклически будут перенаправляться на серверы фермы используя метод round-robin. При этом пакеты принадлежащие одному соединению будут направляться одному серверу ("sticky connection"), но следующее соединение открытое этим же хостом, будет направлено следующему серверу.
Пулы адресов могут использоваться для балансировки нагрузки
между двумя и более внешними каналами с использованием опции
route-to в случае невозможности организовать динамическую
маршрутизацию (например, с использованием протокола BGP4).
Совместное использование route-to
и пула адресов round-robin
позволяет распределить исходящие соединения между разными
провайдерами.
В качестве дополнительной информации необходимо указать
адреса маршрутизаторов для каждого Интернет-соединения. Это
нужно для опции route-to, дабы
управлять исходящими пакетами.
Следующий пример иллюстрирует балансировку нагрузки между двумя каналами:
lan_net = "192.168.0.0/24"
int_if = "dc0"
ext_if1 = "fxp0"
ext_if2 = "fxp1"
ext_gw1 = "68.146.224.1"
ext_gw2 = "142.59.76.1"
pass in on $int_if route-to \
{ ($ext_if1 $ext_gw1), ($ext_if2 $ext_gw2) } round-robin \
from $lan_net to any keep state
Опция route-to используется для
приёма трафика на внутреннем интерфейсе и назначения ему
внешнего сетевого интерфейса и шлюза, таким образом
обеспечивая балансировку. Обратите внимание, что опция
route-to должна быть указана в
каждом правиле, предназначенном для балансировки трафика.
Ответные пакеты приходят на тот интерфейс, с которого ушёл
запрос и они будут перенаправлены во внутрь как обычно.
Для гарантии того, что пакеты с $ext_if1 всегда направляются к $ext_gw1 (и соответственно для $ext_if2 к $ext_gw2), в правилах можно указать следующее:
pass out on $ext_if1 route-to ($ext_if2 $ext_gw2) from $ext_if2 to any
pass out on $ext_if2 route-to ($ext_if1 $ext_gw1) from $ext_if1 to any
NAT можно использовать на каждом внешнем интерфейсе:
nat on $ext_if1 from $lan_net to any -> ($ext_if1)
nat on $ext_if2 from $lan_net to any -> ($ext_if2)
Ниже дан полный пример правил для балансировки внешнего трафика:
lan_net = "192.168.0.0/24"
int_if = "dc0"
ext_if1 = "fxp0"
ext_if2 = "fxp1"
ext_gw1 = "68.146.224.1"
ext_gw2 = "142.59.76.1"
# правила nat для исходящих соединений на каждом внешнем интерфейсе
nat on $ext_if1 from $lan_net to any -> ($ext_if1)
nat on $ext_if2 from $lan_net to any -> ($ext_if2)
# default deny
block in from any to any
block out from any to any
# пропускаем все исходящие пакеты на внутреннем итерфейсе
pass out on $int_if from any to $lan_net
# пропускаем (quick) пакеты предназначенные самому шлюзу
pass in quick on $int_if from $lan_net to $int_if
# балансировка исходящего tcp трафика идущего из внутренней сети
pass in on $int_if route-to \
{ ($ext_if1 $ext_gw1), ($ext_if2 $ext_gw2) } round-robin \
proto tcp from $lan_net to any flags S/SA modulate state
# балансировка исходящего icmp и udp трафика идущего из внутренней сети
pass in on $int_if route-to \
{ ($ext_if1 $ext_gw1), ($ext_if2 $ext_gw2) } round-robin \
proto { udp, icmp } from $lan_net to any keep state
# основные "выпускаюшие" правила на внешнем интерфейсе
pass out on $ext_if1 proto tcp from any to any flags S/SA modulate state
pass out on $ext_if1 proto { udp, icmp } from any to any keep state
pass out on $ext_if2 proto tcp from any to any flags S/SA modulate state
pass out on $ext_if2 proto { udp, icmp } from any to any keep state
# маршрутизация пакетов идущих с любого IP на $ext_if1 через $ext_gw1 и
# пакетов идущих на $ext_if2 через $ext_gw2
pass out on $ext_if1 route-to ($ext_if2 $ext_gw2) from $ext_if2 to any
pass out on $ext_if2 route-to ($ext_if1 $ext_gw1) from $ext_if1 to any
Маркирование пакетов — способ пометить пакет внутренним идентификатором для дальнейшего использования в качестве критерия в правилах трансляции и фильтрации. Маркирование позволяет создать «доверие» между интерфейсами, а так же помогает оределить был ли пакет обработан правилами трансляции. Также становится возможным переход от фильтрации, основанной на правилах, к фильтрации, основанной на политиках.
Для присвоения маркера используется ключевое слово tag:
pass in on $int_if all tag INTERNAL_NET keep state
Маркер INTERNAL_NET будет присвоен
любому пакету соответствующему правилу.
Маркер может быть присвоен с использованием макросов, например:
name = "INTERNAL_NET"
pass in on $int_if all tag $name keep state
Существует набор предопределённых макросов, которые можно использовать для этих целей:
$if$srcaddr$dstaddr$srcport$dstport$proto$nrЭти макросы определяются во время загрузки, а не во время работы.
Маркирование подчиняется следующим правилам:
tag.
Рассмотрим следующий пример:
pass in on $int_if tag INT_NET keep state
В правилах nat, rdr и binat тоже можно метить пакеты при
помощи ключевого слова tag.
Для проверки установленных маркеров используется ключевое
слово tagged:
pass out on $ext_if tagged INT_NET keep state
Это правило соответствует исходящим пакетам на интерфейсе
$ext_if помеченным маркером
INT_NET. Восклицательный знак используется для
инвертирования правила:
pass out on $ext_if ! tagged WIFI_NET keep state
В правилах nat, rdr и binat так же допускается использование
ключевого слова tagged.
Фильтрация пакетов на основе политик несколько отличается от фильтрации на основе правил. В политиках устанавливаются правила, по которым некоторый вид трафика должен быть пропущен, а некоторый запрещён. Пакеты классифицируются внутри политик на основе традиционных критериев — IP адреса источника/назначения, протокола и т.д. Рассмотрим следующий пример:
Заметьте, что политики охватывают весь трафик идущий через брандмауэр. В круглых скобках указаны маркеры используемые для данной политики.
Правила фильтрации и трансляции:
rdr on $ext_if proto tcp from <spamd> to port smtp \
tag SPAMD -> 127.0.0.1 port 8025
nat on $ext_if tag LAN_INET_NAT tagged LAN_INET -> ($ext_if)
block all
pass in on $int_if from $int_net tag LAN_INET keep state
pass in on $int_if from $int_net to $dmz_net tag LAN_DMZ keep state
pass in on $ext_if proto tcp to $www_server port 80 tag INET_DMZ keep state
Таким образом, мы установили какой трафик соответствует какой политике. Теперь разрешим проход трафика принадлежащего политикам SPAMD, LAN_INET_NAT, LAN_DMZ и INET_DMZ:
pass in quick on $ext_if tagged SPAMD keep state
pass out quick on $ext_if tagged LAN_INET_NAT keep state
pass out quick on $dmz_if tagged LAN_DMZ keep state
pass out quick on $dmz_if tagged INET_DMZ keep state
Теперь все политики определены. Если мы захотим добавить
POP3/SMTP сервер в DMZ, нам надо будет добавить следующие
строки в pf.conf(5):
mail_server = "192.168.0.10"
...
pass in on $ext_if proto tcp to $mail_server port { smtp, pop3 } \
tag INET_DMZ keep state
Таким образом, трафик электронной почты будет соответствовать политике INET_DMZ и будет пропущен.
Полный набор правил:
# macros
int_if = "dc0"
dmz_if = "dc1"
ext_if = "ep0"
int_net = "10.0.0.0/24"
dmz_net = "192.168.0.0/24"
www_server = "192.168.0.5"
mail_server = "192.168.0.10"
table <spamd> persist file "/etc/spammers"
# классификация пакетов основанная на определённых в брандмауэре
# политиках
rdr on $ext_if proto tcp from <spamd> to port smtp \
tag SPAMD -> 127.0.0.1 port 8025
nat on $ext_if tag LAN_INET_NAT tagged LAN_INET -> ($ext_if)
block all
pass in on $int_if from $int_net tag LAN_INET keep state
pass in on $int_if from $int_net to $dmz_net tag LAN_DMZ keep state
pass in on $ext_if proto tcp to $www_server port 80 tag INET_DMZ keep state
pass in on $ext_if proto tcp to $mail_server port { smtp, pop3 } \
tag INET_DMZ keep state
# применение политик -- фильтрация на основе опрелелённых в брандмауэре
# политиках
pass in quick on $ext_if tagged SPAMD keep state
pass out quick on $ext_if tagged LAN_INET_NAT keep state
pass out quick on $dmz_if tagged LAN_DMZ keep state
pass out quick on $dmz_if tagged INET_DMZ keep state
Если машина работает как мост на канальном уровне (в
OpenBSD см. bridge(4)
в FreeBSD
if_bridge(4)) пакетный фильтр может
маркировать кадры ethernet. При создании правил трансляции
при помощи команды brconfig(8)
(характерна для OpenBSD) можно установить
маркер с помощью опции tag:
# brconfig bridge0 rule pass in on fxp0 src 0:de:ad:be:ef:0 tag USER1
Далее можно ссылаться на этот маркер в
pf.conf(5):
pass in on fxp0 tagged USER1
Журналирование в пакетном фильтре осуществляется при помощи
демона pflogd(8) слушающего сетевой
интерфейс pflog0 и записывающего
пакеты в журнальный файл /var/log/pflog в
бинарном формате libpcap, который можно просматривать при
помощи программы tcpdump(1) или
wireshark(1), она же
ethereal(1) (см. Раздел 6.11, «Демонстрация основных навыков работы с утилитой
tcpdump(1)»).
У программы tcpdump(1) есть специальные
правила для работы с пакетным
фильтром. Кроме того, программа
tcpdump(1) позволяет просматривать журнал
«на лету» если запустить её на прослушивание
интерфейса pflog0. Для помещения в
журнал, можно применять ключевое слово log (или log
(all)) в правилах фильтрации.
Лирическое отступление:
В 1999 году меня разбил сильный приступ радикулита. Родственник доставили меня в диагностический центр и мне сделали рентген. После рентгена я получил на руки «описание снимка» — в нём было написано шариковой ручкой, что на полученном снимке присутствует позвоночник, к которому прикреплены рёбра. А сам снимок на руки не давали (видимо из-за серебра...). Его давали только врачу, если он сам придёт и попросит.
Многие брандмауэры кладут в журнал сообщение о том, что через них прошёл некоторый пакет. Могут описать его: мол, пакет выглядет так-то и так-то.
Пакетный фильтр кладёт в журнал сами пакеты.
Для журналирования пакета надо поместить ключевое слово log в правило фильтрации, nat или rdr.
Заметьте, что в пактном фильтре нельзя создать правило
только для журналирования пакета — должна
присутствовать либо директива block
либо pass.
Ключевому слову log можно передать
следующие опции:
allkeep state.
userto <interface>
Опции указываются в круглых скобках после ключевого слова
log. Несколько опций можно указать
через запятую или через пробел:
pass in log (all) on $ext_if inet proto tcp to $ext_if port 22 keep state
Это правило помещает в журнал все входящие пакеты, идущие на 22-й порт.
Журнальный файл записанный pflogd(8) имеет бинарный формат, его нельзя читать при помощи текстового редакора. Он предназначен для чтения утилитой tcpdump(1) (или другой программой скомпилированной с поддержкой библиотеки libpcap, например wireshark(1)).
Для просмотра журнального файла выполните команду
# tcpdump -n -e -ttt -r /var/log/pflog
Для просмотра журнала в режиме реального времени:
# tcpdump -n -e -ttt -i pflog0
| Внимание |
|---|---|
При чтении журнала с применением режима verbose
(активируется флагом Кроме того, имейте в виду, что pflogd(8) по умолчанию помещает в журнал первые 96 байт пакета. В этих байтах могут находиться критические данные, такие как пароли telnet(1) или ftp(1). |
Поскольку pflogd(8) сохраняет данные в формате tcpdump(1), при просмотре данных журнала можно использовать правила фильтрации tcpdump(1). Например, для просмотра данных касающихся некоторого конкретного порта можно применять команду:
# tcpdump -n -e -ttt -r /var/log/pflog port 80
Этот пример можно слегка изменить, чтобы ограничить фильтрацию некоторым конкретным хостом:
# tcpdump -n -e -ttt -r /var/log/pflog port 80 and host 192.168.1.3
Та же идея может использоваться при чтении данных из
устрйства pflog0:
# tcpdump -n -e -ttt -i pflog0 host 192.168.4.2
Правила фильтрации в tcpdump(1) специально расширены для взаимодействия с pflogd(8). В данной работе синтаксис правил tcpdump(1) подробно рассмотрен в Раздел 6.11, «Демонстрация основных навыков работы с утилитой tcpdump(1)», в том же разделе рассматриваются дополнительные правила tcpdump(1) для работы с журналом pflogd(8).
Ещё один пример:
# tcpdump -n -e -ttt -i pflog0 inbound and action block and on wi0
В этом примере мы в режиме реального времени следим за
входящими пакетами блокирующимися на интерфейсе wi0.
Во многих случаях желательно вести журнал брандмауэра в текстовом формате и отправлять данные журнала на внешний журнальный сервер.
Увы, никакого естественного метода для этого документация по пакетному фильтру нам не предлагает. Всё что нам предлагают, это раз в 5 минут пропускать бинарный файл через pipe:
# tcpdump -n -e -ttt -r /var/log/pflog | logger -t pf -p local0.info
Пошаговое HOWTO для направления данных журнала через logger(1) демону syslogd(8) можно найти на сайте разработчиков пакетого фильтра. Я не планирую пересказывать эту методику в данной книге, так как считаю её увечной.
Насколько большую полосу пропускания может обслуживать пакетный фильтр? Насколько мощный компьютер мне нужен для обслуживания соединений с Интернет?
Простого ответа на эти вопросы нет. Для некоторых целей будет достаточно процессора 486/66 с парой хороших сетевых карт ISA, при этом будет происходить трансляция NAT и обрабатываться трафик до 5 Mdbs. Для других целей может не будет хватать даже более быстрой машины с более мощными сетевыми интерфейсами. Оценивать следует не количество байт в секунду, а количество пакетов в секунду.
Производительность пакетного фильтра определяется несколькими величинами:
keep
state и quick тем лучше
производительность. Чем больше правил через которые пройдёт
пакет, тем хуже производительность.
Часто люди спрашивают про benckmark для пакетного фильтра. Benchmark для вашей системы с вашим окружением можете сделать только вы.
Пакетный фильтр используют на некоторых очень больших системах с очень большим трафиком. Разработчики — люди компетентные. Это не плохая для вас новость.
Подробнее вопросы производительности пакетного фильтра изложены в работе Дэниэла Хартмайера [url://Hartmeier-2006-en], [url://Hartmeier-2006-ru].
FTP это протокол, который создавался, когда Интернет был маленький и все в нём друг друга знали. Нужды в фильтрации трафика в те годы не было, поэтому FTP сконструирован без оглядки на брандмауэры и трансляцию NAT.
Существует два режима функционирования FTP: пассивный и активный. Выбор между ними, это выбор между тем, у кого будут проблемы с фильтрацией трафика. Если вы хотите, чтобы ваши пользователи были счастливы, вам придётся приспособиться к обоим режимам.
Активный FTP. Когда клиент посылает серверу команду о передаче данных, сервер «ведёт себя активно» — открывает соединение к клиенту. Клиент выбирает случайный верхний порт и сообщает его серверу, последний открывает соединение на указанный порт клиента для передачи данных. Такое поведение затрудняет работу NAT: FTP сервер пытается открыть соединение с машиной, на которой работает NAT, а он просто не знает, что делать с этими соединениями.
Пассивный FTP. При передаче данных сервер выбирает случайный верхний порт и сообщает его клиенту. Клиент открывает соединение на указанный верхний порт сервера, и по этому соединению передаются данные. Такая практика не всегда возможна и не всегда желательна, так как брандмауэр может блокировать трафик идущий на эти случайные порты. Зато с NAT с клиентской стороны, напротив нет никаких проблем, так как все соединения идут от клиента к серверу.
Для тестирования можно применять программу
ftp(1). В всех системах
BSD эта программа по умолчанию работает в
пассивном режиме. В активный режим её можно перевести с
использованием аргумента -A или уже во
время работы при помощи команды passive
off отданной в ответ на приглашение ftp>passive
on).
Как сказано выше протокол FTP плохо взаимодействует с брандмауэрами и NAT.
Для решения этой проблемы пакетный фильтр предлагает воспользоваться прокси сервером FTP. Этот процесс пропускает FTP трафик добавляя и удаляя правила в пакетный фильтр при помощи системы якорей. Демон ftp-proxy(8) используется пакетным фильтром в OpenBSD 3.9. В старых версиях существовал другой демон с тем же названием.
Чтобы использовать его, поместите следующие строки в раздел
NAT файла /etc/pf.conf(5):
nat-anchor "ftp-proxy/*"
rdr-anchor "ftp-proxy/*"
rdr on $int_if proto tcp from any to any port 21 -> 127.0.0.1 port 8021
Первые два правила создают пару якорей, которые будут использоваться демоном ftp-proxy(8) для добавления и удаления правил, т.е. для управления трафиком FTP.
Последняя строка перенаправляет трафик FTP от клиентов программе ftp-poxy(8), которая будет слушать порт 8021.
Вам так же понадобится якорь в области фильтрации:
anchor "ftp-proxy/*"
Вам так же понадобится сделать так, чтобы демон
ftp-proxy(8) стартовал при запуске
системы. Для этого в OpenBSD надо в файл
/etc/rc.conf.local добавить строку:
ftpproxy_flags=""
Можно запустить программу вручную, чтобы не перезагружать машину.
Для работы активного FTP вам понадобится ключ
-r для ftp-proxy(8)
В FreeBSD и NetBSD
функциональность ftp-proxy(8) ниже, чем
в OpenBSD. Фактически, в этих системах
пока применяется устаревшая версия
ftp-proxy(8).
Вместо ftp-proxy(8) в этих системах
можно использовать порт
ftp/ftpsesame. См. Раздел C.5.3, «ftpsesame». Далее описано, как
используется старая версия программы
ftp-proxy(8), которой укомплектована
FreeBSD.
В FreeBSD
ftp-proxy(8) запускается из
суперсервера inetd(8). Для этого в
/etc/pf.conf(5) мы добавляем примерно
такое правило:
int_if = "xl0"
rdr pass on $int_if proto tcp from any to any port 21 -> 127.0.0.1 port 8021
Затем мы конфигурируем inetd(8) так,
чтобы он начал слушать порт 8021. Для этого в файл
/etc/inetd.conf вписываем строку:
ftp-proxy stream tcp nowait root /usr/libexec/ftp-proxy ftp-proxy
Таким образом, ftp-proxy(8) пробрасывает командный канал FTP, а для передачи данных необходимо добавить разрешающие правила в брандмауэр:
block in on $ext_if proto tcp all
pass in on $ext_if inet proto tcp from any to $ext_if \
port > 49151 keep state
Это правило разрешает подключение к портам от 49151 до
65535. Программе ftp-proxy(8) можно
задавать диапазоны портов при помощи опций
-m и -M. Подробнее см.
man(1) по команде
ftp-proxy(8). Диапазон портов
используемых демоном ftpd(8) в
FreeBSD можно регулировать при помощи
переменных ядра net.inet.ip.portrange.first net.inet.ip.portrange.last, а в
OpenBSD net.inet.ip.porthifirst и net.inet.ip.porthilast.
Надо признать, что вариант с динамическими правилами,
работающий в OpenBSD выглядит разумнее.
Остаётся надеяться, что в будущем он будет портирован в
FreeBSD, а пока, повторюсь, мы можем
использовать порт ftp/ftpsesame.
При функционировании пакетного фильтра и FTP сервера на
одной машине достаточно разрешить в обе стороны коннекты в
диапазоне портов от 49151 до 65535. Этот диапазон портов
используется по умолчанию системным FTP серврером
ftpd(8). Диапазон портов можно
регулировать в FreeBSD при помощи
переменных ядра net.inet.ip.portrange.first net.inet.ip.portrange.last, а в
OpenBSD net.inet.ip.porthifirst и net.inet.ip.porthilast.
pass in on $ext_if proto tcp from any to any port 21 keep state
pass in on $ext_if proto tcp from any to any port > 49151 keep state
В этом случае брандмауэр должен перенаправлять FTP трафик сервера и не блокировать нужные порты. Для этого мы вновь приходим к необходимости использовать ftp-proxy(8).
ftp-proxy(8) может быть запущен в режиме перенаправления всего FTP трафика на один сервер FTP. Обычно мы настраиваем брандмауэр так, чтобы он слушал порт 21 и пробрасываем трафик на внутренний сервер FTP:
ftpproxy_flags="-R 10.10.10.1 -p 21 -b 192.168.0.1"
Здесь 10.10.10.1 — адрес сервера FTP, а работает он на порту 21. 192.168.0.1 — внешний адрес брандмауэра, к которому мы привязываем программу ftp-proxy(8).
Правила pf.conf:
ext_ip = "192.168.0.1"
ftp_ip = "10.10.10.1"
nat-anchor "ftp-proxy/*"
nat on $ext_if inet from $int_if -> ($ext_if)
rdr-anchor "ftp-proxy/*"
pass in on $ext_if inet proto tcp to $ext_ip port 21 \
flags S/SA keep state
pass out on $int_if inet proto tcp to $ftp_ip port 21 \
user proxy flags S/SA keep state
anchor "ftp-proxy/*"
Опция user proxy нужна для того,
чтобы убедиться, что только программа
ftp-proxy(8) может пробрасывать пакеты.
| Замечание |
|---|---|
В FreeBSD и NetBSD
вместо ftp-proxy(8) можно использовать
порт ftp/ftpsesame. См. Раздел C.5.3, «ftpsesame».
|
authpf(8) — пользовательская
оболочка для авторизации на шлюзе. При использовании этой
программы шлюз работает как обычный маршрутизатор, но
пропускает пользовательский трафик только если пользователь
аутентифицировался на нём. Если пользовательская оболочка
выставлена в /etc/sbin/authpf (т.е.
вместо csh(1) и пр.) и пользователь зашёл в
систему, например через ssh(1),
authpf(8) динамически настраивает пакетный
фильтр так, чтобы он начал пропускать трафик пользователя,
осуществлял нужные пользователю перенаправления и трансляции.
Когда пользователь прекращает сессию
ssh(1), authpf(8)
удаляет правила из пакетного фильтра и удаляет записи из
таблицы состояний. Таким образом, пользователь способен
сохранять соединение только пока открыта сесстия
ssh(1).
authpf(8) загружает правила фильтрации и
трансляции используя уникальный для каждого пользователя
якорь. Название
якоря является комбинацией из имени пользователя и PID
экземпляра authpf(8) в формате username(PID). Каждый пользовательский
якорь находится внутри якоря authpf, который уже находится в
основном наборе правил. Таким образом, «полностью
разрешённое имя якоря» выглядит как
main_ruleset/authpf/username(PID)
Правила, которые может загрузить authpf(8) могут быть индивидуальными для каждого пользователя, а могут быть глобальными.
Вот примеры использования authpf(8):
Информация об аутентифицировавшихся пользователях журналируется через syslogd(8). Это позволяет администратору вычислять кто когда пользовался интернетом и вычислять какой пользователь испольоваал большее количество трафика.
Полностью конфигурирование authpf(8) описано в man(1) странице по authpf(8).
В системе должен существовать конфигурационный файл
/etc/authpf/authpf.conf. В нём
содержатся конфигурационные опции
authpf(8). Если файла не существует,
authpf(8) будет завершать работу сразу
после аутентификации. Если он существует, но пуст, будут
использованы умолчания.
В этом файле могут присутствовать следующие две опции:
authpf(8) помещается в основной набор
правил при помощи правила anchor:
nat-anchor "authpf/*"
rdr-anchor "authpf/*"
binat-anchor "authpf/*"
anchor "authpf/*"
Пакетный фильтр перейдёт к изучению правил входящих в эти якоря там, где они расположены. Нет нужды всегда использовать все якоря. Например, если authpf(8) не настроен на то, чтобы осуществлять трансляцию NAT, то соответствующий якорь не нужен.
authpf(8) погружает правила из файлов
/etc/authpf/users/$USER/authpf.rules/etc/authpf/authpf.rulesСперва ищется первый, потом второй, если существуют оба — используется только один. Таким оразом, в первом файле должны находится правила характерные для конкретного пользователя и они будут перебивать глобальные правила заданные во втором файле. Как минимум один файл должен существовать, иначе authpf(8) не запустится.
Правила трансляции такие же как и в основном файле, однако определены два макроса:
$user_ip$user_id
Рекомендуется использовать $user_id для того, чтобы был
разрешён только трафик с пользовательской машины.
В добавок к макросу $user_ip
authpf(8) может использовать для
хранения всех аутентифицировавшихся пользователей таблицу
authpf_users если она
существует. Убедитесь, что вы определили её, прежде чем
использовать:
table <authpf_users> persist
pass in on $ext_if proto tcp from <authpf_users> \
to port smtp flags S/SA keep state
Эта таблица должна использоваться в правилах, которые относятся ко всем аутентифицировавшимся пользователям.
Пользователям можно запретить пользоваться
authpf(8) для этого надо создать файл в
каталоге /etc/authpf/banned/. Файл
должен называться по имени пользователя. Его содержимое
будет показано пользователю перед обрывом связи. Таким
образом, в нём можно указать причины прекращения доступа и
как связаться с ответсвенным лицом.
Кроме того, в файле
/etc/authpf/authpf.allow можно
перечислить пользователей, которым разрешено входить в
систему с использованием authpf(8).
Если файл существует, действует политика «что не
разрешено, то запрещено». Если файла нет, или если в
нём звёздочка * —
authpf(8) позволяет зайти всем, кто
успешно залогинился через ssh(1), если
только его не «забанили» в каталоге
/etc/authpf/banned/.
Если authpf(8) не может определить
разрешено польователю входить или нет, он печатает
предупреждение и не пускает пользователя.
/etc/authpf/banned/ всегда главнее
/etc/authpf/authpf.allow.
Когда пользователь успешно аутентифицируется в системе, ему будет напечатано приветственное сообщение
Hello charlie. You are authenticated from host "64.59.56.140"
Это сообщение можно дополнить сообщением из файла
/etc/authpf/authpf.message.
Чтобы authpf(8) заработал, его надо сделать оболочкой пользователя. Когда пользователь успешно зайдёт в систему через ssh(1), authpf(8) будет запущен в качестве оболочки. Он проверит можно ли пользователю его использовать, загрузит нужные правила и т.д.
Есть два способа назначить пользователю authpf(8) в качестве оболочки:
login.conf(5).
(см. Приложение F, /etc/login.conf(5)).
| Замечание |
|---|---|
Что такое классы, зачем они нужны, как их создавать,
подробно описано в Приложение F, /etc/login.conf(5).
|
В системе где есть одновременно обычные пользователи и пользователи для authpf(8) удобно создать для последних специальный класс. Это позволит сделать разные политики для разных пользователей. Например, в классе можно указать:
shell/usr/sbin/authpf так, что её
невозможно будет сменить через программу
chsh(1) — эта опция
login.conf(5) имеет приоритет перед
содержимым файла passwd(5).
welcome
Класс создаётся в файле
/etc/login.conf. Вот пример класса для
пользователей authpf(8):
authpf:\
:welcome=/etc/motd.authpf:\
:shell=/usr/sbin/authpf:\
:tc=default:
После редактирования файла
/etc/login.conf не забудьте выполнить
команду
# cap_mkdb /etc/login.conf
Назначить пользователю класс можно разными способами. Например: chsh(1), pw(8), vipw(8).
Чтобы просмотреть список пользователей из класса authpf можно выполнить такую команду:
# awk -F: '$5=="authpf"{print $1}' /etc/master.passwd | sort
После того, как пользователь успешно вошёл в систему, authpf(8) меняет заколовок процесса, помещая в него имя пользователя и IP адрес с которого он пришёл:
$ ps -ax | grep authpf
23664 p0 Is+ 0:00.11 -authpf: charlie@192.168.1.3 (authpf)
Послав этому процессу сигнал SIGTERM
можно насильно прервать логин пользователя. При этом
authpf(8) удалит все правила из пакетного
фильтра и прекратит коннект пользователя.
А если послать сигнал SIGKILL,
то не удалит, и пользователь по прежнему будет ходить через
шлюз!
# kill -TERM 23664
Пусть пакетный фильтр используется на машине
OpenBSD, которая является шлюзом для
беспроводной сети, которая является частью большой
университетской сети. Если пользователь аутентифицировался,
и он не находится в списке запрещённых пользователей
(/etc/authpf/banned/), ему разрешают
SSH наружу, использовать web, и, конечно, открывают доступ к
DNS.
Файл /etc/authpf/authpf.rules содержит
следующие строки:
wifi_if = "wi0"
pass in quick on $wifi_if proto tcp from $user_ip to port { ssh, http, \
https } flags S/SA keep state
Администратор charlie должен иметь доступ к SMTP, POP3, а так же web и SSH.
Файл
/etc/authpf/users.charlie/authpf.rules
содержит следующие строки:
wifi_if = "wi0"
smtp_server = "10.0.1.50"
pop3_server = "10.0.1.51"
pass in quick on $wifi_if proto tcp from $user_ip to $smtp_server \
port smtp flags S/SA keep state
pass in quick on $wifi_if proto tcp from $user_ip to $pop3_server \
port pop3 flags S/SA keep state
pass in quick on $wifi_if proto tcp from $user_ip to port { ssh, http, \
https } flags S/SA keep state
Основной файл с правилами, расположенный в
/etc/pf.conf содержит следующие строки:
# macros
wifi_if = "wi0"
ext_if = "fxp0"
dns_servers = "{ 10.0.1.56, 10.0.2.56 }"
table <authpf_users> persist
scrub in all
# filter
block drop all
pass out quick on $ext_if inet proto tcp from \
{ $wifi_if:network, $ext_if } flags S/SA modulate state
pass out quick on $ext_if inet proto { udp, icmp } from \
{ $wifi_if:network, $ext_if } keep state
pass in quick on $wifi_if inet proto tcp from $wifi_if:network to $wifi_if \
port ssh flags S/SA keep state
pass in quick on $wifi_if inet proto { tcp, udp } from <authpf_users> \
to $dns_servers port domain keep state  anchor "authpf/*" in on $wifi_if
anchor "authpf/*" in on $wifi_if 
Правила очень просты. Вот, что они значат:
Основная идея в том, чтобы заблокировать всё и открыть
настолько мало, насколько это возможно. Трафик может
свободно покидать внешний интерфейс, однако он заблокирован
политикой default deny на внутреннем (wi0) интерфейсе. Когда
пользователь аутентифицируется, его трафик оказывается
разрешён для прохода на внутреннем интерфейсе и, таким
образом, проходит наружу. Ключевое слово quick используется для того, чтобы
добавляемые на лету правила не сказывались на конструкции
брандмауэра.
CARP — Common Address Redundancy Protocol (Общий Протокол Избыточных Адресов, я не знаю есть ли общепринятый перевод на русский язык). Основная задача протокола — дать возможность различным хостам в локальной сети использовать общий IP адрес. CARP является свободной и безопасной альтернативой протоколам VRRP (Virtual Router Redundancy Protocol, см. [RFC-3768]) и HSRP (Hot Standby Router Protocol, см. [RFC-2281]). К сожалению на этот протокол не опубликовано RFC. Кроме того, уже сужествует другой протокол с тем же названием: (Cache Array Routing Protocol, [RFC-3040] — протокол используемый Microsoft ISA).
История вопроса такова (по данным wikipedia): В конце 90-х годов IETF начало работу над проблемой отказоустойчивости сервисов. В 1997 году Cisco проинформировало, что проблема уже решена при помощи запатентованной ими технологии. В 1998 году Cisco опубликовала запатентованный протокол HSRP. Несмотря на это IETF продолжила работу над своим протоколом VRRP. После некоторых дебатов было решено, что запатентованную технологию можно использовать в качестве стандарта при условии лицензирования по «разумной и не дискриминационной» лицензии. Однако, поскольку VRRP решало некоторые проблемы HSRP сама Cisco перешла на использование VRRP при этом называя его своим.
Cisco проинформировала разработчиков OpenBSD, что они не могут использовать патентованный VRRP. Возможно это было связано с судебными тяжбами Cisco с Alkatel (звучит загадочно — Е.М.). Таким образом, свободную реализацию VRRP сделать было нельзя, поэтому OpenBSD принялись за разработку альтернативного протокола CARP.
В настоящий момент CARP реализован не только в OpenBSD, но так же портирован в FreeBSD и NetBSD (и, следовательно в DragonFly BSD).
IANA до сих по не выделила официальный номер протокола для CARP. Это связано, по всей видимости, с отсутствием его описания. Разработчики OpenBSD самовольно присвоили ему номер 112 (конфликтующий с VRRP). То же касается и протокола
pfsync.
CARP позволяет группе хостов использовать общий IP адрес. Эта группа хостов называется «избыточная группа» (redundancy group). Избыточной группе присваивается общий адрес, затем, среди её членов назначается «мастер» и запасные машины (backup). Мастер, это та машина, которой в данный момент принадлежит общий адрес IP. Он отвечает на ARP запросы, обращённые к этому адресу. Каждый хост может принадлежать более чем к одной «избыточной группе».
Один из способов использования CARP — построение избыточных брандмауэров. Виртуальный IP адрес, принадлежащий группе, указывают клиентам в качестве маршрута по умолчанию. Если брандмауэр оказывается недоступен, IP адрес переходит к другой, запасной машине в группе и работа сети продолжается.
Мастер-хост группы регулярно посылает оповещения в локальную
сеть, чтобы запасные хосты знали, что он ещё жив. Если
запасной хост в течении некоторого времени не получает
уведомления от мастера, то он может принять на себя
обязанности мастера. (Какой именно — зависит от
значения advbase и advskew).
В одной локальной сети может находиться несколько групп CARP, так как в оповещении, рассылаемом мастером присутствует Virtual Host ID, по которому запасные машины могут понять какой группе адресовано оповещение.
Чтобы предотвратить рассылку поддельных оповещений CARP, каждая группа может быть сконфигурирована с паролем. Каждый пакет CARP снабжается этим паролем в виде SHA1 HMAC.
CARP рассылается при помощи собственного протокола сетевого уровня (номер 112, официально не утверждён IANA) и ему нужно отдельное правило в брандмауэре:
pass out on $carp_dev proto carp keep state
Здесь $carp_dev —
физический интерфейс через который передаются оповещения
CARP.
Каждая группа CARP представлена
виртуальным сетевым интерфейсом carp(4). Таким образом,
CARP можно настроить используя команду
ifconfig(8):
#ifconfig <carpN> create#ifconfig <carpN> vhid <vhid> [pass <password>] [carpdev <carpdev>] \ [advbase <advbase>] [advskew <advskew>] [state <state>] <ipaddress> \ netmask <mask>
carpNN — целое число,
номер интерфейса, например 10.
vhidpasswordcarpdevadvbaseadvskewadvbase.
На основе величин advbase и
advskew происходит выбор
мастера в группе: чем меньше advbase, который может
использовать хост, тем выше у него приоритет. По
умолчанию 0. Допустимые значения от 0 до 254.
stateinit, backup, master. Аргумент отсутствует в
FreeBSD.
ipaddressmaskПоведением CARP пожно управлять через sysctl(8). Вот некоторые переменные ядра:
Приведённые ниже переменные ядра работают как в OpenBSD, так и в FreeBSD:
net.inet.carp.allownet.inet.carp.preempt
Позволяет мастеру передать его обязанности другим
членам группы CARP имеющим лучшие
показатели advbase и advskew. Кроме того, позволяет
обработать ситуацию отказа — если
физический интерфейс отказал, на других интерфейсах с
включённым CARP advskew выставляется в 240.
Поясню: Пусть имеется маршрутизатор A с двумя
интерфейсами в CARP и advskew=0 и маршрутизатор B с
advskew=100. Если данная
переменная ядра выставлена в истину, и на
маршрутизаторе A падает один интерфейс. В этом случае
advskew на A увеличивается
до 240 и обязанности мастера берёт маршрутизатор B.
По умолчанию выставлен в 0 (нет)
net.inet.carp.lognet.inet.carp.arpbalance
Дополнительную информацию можно получить из руководства
man(1) по carp(4) и из [url://Sgibnev-CARP-2006].
Пример конфигурации CARP:
#sysctl -w net.inet.carp.allow=1#ifconfig carp1 create#ifconfig carp1 vhid 1 pass mekmitasdigoat carpdev em0 \ advskew 100 10.0.0.1 netmask 255.255.255.0
Чтобы просмотреть состояние интерфейса carp1 мы можем вновь использовать
команду ifconfig(8)
$ ifconfig carp1
carp1: flags=8802<UP,BROADCAST,SIMPLEX,MULTICAST> mtu 1500
carp: BACKUP carpdev em0 vhid 1 advbase 1 advskew 100
groups: carp
inet 10.0.0.1 netmask 0xffffff00 broadcast 10.0.0.255
Интерфейс pfsync(4) используется
для наблюдения за таблицей состояний пакетного фильтра. При
помощи утилиты tcpdump(8) можно следить
за таблицей состояний в режиме реального времени. Кроме
того, pfsync(4) позволяет
посылать информацию об изменениях в таблице состояний по
сети. Таким образом, другие пакетные фильтры на других
машинах могут заносить эту информацию в свои таблицы. Таким
образом, pfsync(4) позволяет
модифицировать таблицы состояния по сети.
По умолчанию pfsync(4) не
получает и не отсылает информации о состоянии соединений.
Это не мешает следить за его деятельностью локально, при
помощи tcpdump(8).
Когда pfsync(4) конфигурируется
для отправки или получения информации, он начинает рассылать
её при помощи multicast пакетов в локальной сети. Все
оповещения pfsync(4) отсылает без
аутентификации. Наилучшая практика состоит в том, чтобы:
syncdev (см. ниже).
syncpeer (см. ниже). Это приведёт к
тому, что информация будет отсылаться по unicast адресу.
Затем надо зашифровать трафик между партнёрами при помощи
ipsec(4).
При обмене сообщениями pfsync(4)
надо сконфигурировать пакетный фильтр так, чтобы он начал
этот трафик пропускать (pfsync использует свой протокол
сетевого уровня, номер 240, этот номер официально не
утверждён IANA):
pass on $sync_if proto pfsync
Здесь $sync_if —
интерфейс, через который идёт обмен информацией.
Поскольку pfsync(4) —
виртуальный сетевой интерфейс, его можно конфигурировать
используя ifconfig(8):
ifconfig <pfsyncN> syncdev <syncdev> [syncpeer <syncpeer>]
pfsyncNpfsync(4). При
использовании ядра GENERIC интерфейс pfsync0 существует по умолчанию.
Это относится и к OpenBSD и к
FreeBSD.
syncdevpfsync(4) для сетевых обновлений.
syncpeerpfsync(4) использует адрес
multicast, а с данной опцией использует unicast.
Пример:
# ifconfig pfsync0 syncdev em1
Эта команда включает pfsync(4) на
интерфейсе em1. Исходящие пакеты
отправляются при помощи multicast и доступны всем хостам в
сети, на которых запущен pfsync.
Совместное использование CARP и pfsync позволяет создать два и более брандмауэра и объединить их в устойчивый полнофункциональный кластер. При этом CARP реализует отказоустойчивую систему, а pfsync позволяет синхронизировать данные таблиц состояния, так, что при отказе мастера, запасная машина берёт на себя его функции и при этом не обрывает имеющиеся соединения.
Например, пусть у нас имеется два брандмауэра — fw1 и fw2:
+----| WAN/Internet |----+
| |
| общий адрес |
| +----192.0.2.100-----+ |
| | | |
192.0.2.1:em2|/ \|em2:192.0.2.2
+-----+ 10.10.10.2+-----+
| fw1 |-em1----------em1-| fw2 |
+-----+10.10.10.1 +-----+
172.16.0.1:em0|\ /|em0:172.16.0.2
| | | |
| +----172.16.0.100----+ |
| общий адрес |
| |
---+-------Shared LAN-------+---
Брандмауэры соединены «спина к спине» через кросс через интерфейсы em1. Оба соединены с локальной сетью при помощи интерфейсов em0 и с внешней сетью через интерфейсы em2. Адреса показаны на схеме. Мастер — fw1.
Конфигурируем fw1:
Выполняем необходимые настройки в ядре:#sysctl -w net.inet.carp.preempt=1 Настраиваем pfsync#ifconfig em1 10.10.10.1 netmask 255.255.255.0#ifconfig pfsync0 syncdev em1#ifconfig pfsync0 up Настраиваем CARP на внутреннем интерфейсе#ifconfig carp1 create#ifconfig carp1 vhid 1 carpdev em0 pass lanpasswd \ 172.16.0.100 netmask 255.255.255.0 Настраиваем CARP на внешнем интерфейсе#ifconfig carp2 create#ifconfig carp2 vhid 2 carpdev em2 pass netpasswd \ 192.0.2.100 netmask 255.255.255.0
Конфигурируем fw2:
Выполняем необходимые настройки в ядре:#sysctl -w net.inet.carp.preempt=1 Настраиваем pfsync#ifconfig em1 10.10.10.2 netmask 255.255.255.0#ifconfig pfsync0 syncdev em1#ifconfig pfsync0 up Настраиваем CARP на внутреннем интерфейсе#ifconfig carp1 create#ifconfig carp1 vhid 1 carpdev em0 pass lanpasswd \ advskew 128 172.16.0.100 netmask 255.255.255.0 Настраиваем CARP на внешнем интерфейсе#ifconfig carp2 create#ifconfig carp2 vhid 2 carpdev em2 pass netpasswd \ advskew 128 192.0.2.100 netmask 255.255.255.0
Некоторые распространённые проблемы при использовании
CARP и pfsync(4).
И carpN и pfsyncN являются сетевыми
интерфейсами и настраиваются так как дожны настраиваться
обычные сетевые интерфейсы (см: Раздел 6.2.6, «Как сохранить установленные сетевые параметры»). В OpenBSD
создаётся файл hostname.if:
Файл /etc/hostname.carp1:
inet 172.16.0.100 255.255.255.0 172.16.0.255 vhid 1 carpdev em0 \
pass lanpasswd
Файл /etc/hostname.pfsync0:
up syncdev em1
В FreeBSD вам понадобятся следующие
строки в /etc/rc.conf:
ifconfig_carp1="172.16.0.100/24 vhid 1 carpdev em0 pass lanpasswd"
ifconfig_pfsync0="up suncdev em1"
Иногда бывает нужно перенести мастера с одного хоста на другой. Например, надо останивить мастера для профилактических работ или для отладки. Здесь обсуждается как это сделать не вредя имеющимся коннектам, чтобы пользователи ничего не заметили.
Для этих целей вы можете остановить интерфейс carp. Мастер при этом выставит
бесконечно большое значение advbase и advskew запасные машины немедленно
это обнаружат и одна из них примет на себя обязанности
мастера.
# ifconfig carp1 down
Другой вариант состоит в том, что вы увеличиваете значение
advbase и advskew при этом обязанности
мастера перейдут к запасной машине, но данная машина не
будет удалена из группы CARP.
Третий вариант состоит в том, чтобы управлять
CARP'ом при помощи переменной
demotion. Эта возможность пока
реализована только в OpenBSD.
| Внимание |
|---|---|
Описанный механизм связанный с переменной
demotion работает только в
OpenBSD.
|
Переменная demotion присваивается
группе интерфейсов. Повышая эту величину вы можете
опустить CARP на заданной группе
интерфейсов. Текущее значение demotion
можно увидеть при помощи команды
ifconfig(8):
$ ifconfig -g carp
carp: carp demote count 0
Здесь показано значение ассоциированное с группой carp.
Рассмотрим такой пример: имеется два брандмауэра с запущенным CARP со следующими CARP интерфейсами:
carp1carp2carp3carp4
Задача состоит в том, чтобы перенести группы carp1 и carp2 на второй сервер.
Для начала присвоим эти интерфейсы группе «internal»:
#ifconfig carp1 group internal#ifconfig carp2 group internal$ifconfig internal carp1: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500 carp: MASTER carpdev em0 vhid 1 advbase 1 advskew 100 groups: carp internal inet 10.0.0.1 netmask 0xffffff00 broadcast 10.0.0.255 carp2: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500 carp: MASTER carpdev em1 vhid 2 advbase 1 advskew 100 groups: carp internal inet 10.0.1.1 netmask 0xffffff00 broadcast 10.0.1.255
Теперь увеличим счётчик demotion для группы internal при
помощи ifconfig(8):
$ifconfig -g internal internal: carp demote count 0#ifconfig -g internal carpdemote 50$ifconfig -g internal internal: carp demote count 50
Теперь CARP передаст полномочия по
интерфейсам carp1 и carp2 на вторую машину, но
останется мастером для carp3 и
carp4.
Чтобы вернуть полномчия обратно надо выполнить команду:
#ifconfig -g internal -carpdemote 50$ifconfig -g internal internal: carp demote count 0
Некоторые сетевые демоны, такие как
OpenBGPD и
sasyncd(8) используют счётчик
demotion для того, чтобы перед тем как
установить BGP сессию или перед тем как синхронизировать
IPSec SA, выяснить — является ли брандмауэр
мастером.
Фильтр должен работать на физическом
интерфейсе, не на виртуальном интерфейсе carp0. Напрмер:
pass in on fxp0 inet proto tcp from any to carp0 port 22
Если вы замените fxp0 на carp0 правило будет работать не
так, как вы этого ожидаете.
| Замечание |
|---|---|
Не забывайте пропускать протокол CARP
при помощи правила proto carp и
трафик proto pfsync.
|
В данном примере пакетный фильтр используется как брандмауэр и NAT в домашней сети или небольшом офисе. Задача состоит в том, чтобы обеспечить доступ из внутренней сети в Интернет, обеспечить ограниченный доступ к брандмауэру из Интернета и обеспечить доступ к внутреннему web-серверу из Интернет.
Топология сети:
WWW-server
[ COMP1 ] [ COMP3 ]
| |
---+------+-----+------- xl0 [ BSD ] fxp0 -------- ( Internet )
|
[ COMP2 ]
Во внутренней сети есть некоторое количество компьютеров. Сколько именно — неважно. У нас на диаграмме показано три. На компьютере COMP3 работает небольшой web-сервер. Внутренняя сеть 192.168.0.0/24
Брандмауэр работает на OpenBSD (или любй
другой BSD) на процессоре
Celeron 300MHz с двумя сетвыми картами: 3com 3c905B
(xl0) и Intel EtherExpress
Pro/100 (fxp0). Брандмауэр
соединён кабелем FastEthernet с провайдером. Для выхода
внутренних машин в сеть используется NAT. Внешний адрес
назначается провайдером динамически.
Разрешить следующий входящий трафик:
Мы считаем, что машина сконфигурирована как шлюз (т.е. включён проброс пакетов с интерфейса на интерфейс) и пакетный фильтр включён. О том как это делать написано в Раздел C.1, «Введение в работу с пакетным фильтром OpenBSD».
Определяем макросы для облегчения управления брандмауэром и упрощения набора правил:
ext_if="fxp0"
int_if="xl0"
tcp_services="{ 22, 113 }"
icmp_types="echoreq"
comp3="192.168.0.3"
Первые две строки определяют сетевые интерфейсы брандмауэра. Если нам придётся перенести брандмауэр с машины на машину, нам надо будет изменить только эти две строчки, остальные правила будут по прежнему работоспособны. Третья и червёртая строки определяют номера открытых портов и типы ICMP сообщений принимаемых шлюзом. В последней строке задан адрес машины COMP3.
| Замечание |
|---|---|
Если соединение установлено через PPPoE, NAT трансляция
должна осуществляться на интерфейсе tun0, не на fxp0.
|
Следующие две опции определяют поведение системы при блокировании пакетов и включают журналирование для внешнего интерфейса:
set block-policy return
set loginterface $ext_if
Каждая UNIX-система имеет кольцевой интерфейс, необходимый для того, чтобы программы могли общаться друг с другом при помощи сетевых протоколов внутри машины. Фильтрацию на кольцевом интерфейсе лучше отключить — чтобы не мешать работе программ.
set skip on lo
| Замечание |
|---|---|
В OpenBSDlo
это группа кольцевых интерфейсов, поэтому при появлении
нового сетевого интерфейса вам не придётся ни о чём
специально заботиться. В остальных системах,
FreeBSD, NetBSD,
DragonFly BSD, вам придётся
определить эту опцию отдельно для каждого сетевого
интерфейса lo0, lo1 и т.д. (Случай когда их больше
одного не част).
|
Нет причин не использовать рекомендованные алгоритмы нормализации трафика. Поэтому нормализация, это всего одна строка:
scrub in
Следующее правило используется для трансляции NAT всей внутренней сети:
nat on $ext_if from !($ext_if) to any -> ($ext_if)
Мы можем заменить !($ext_if) на
$int_if, но тогда нам придётся
добавлять правила в брандмауэр, если мы добавим в шлюз ещё
один интерфейс, который будет смотреть в другую внутреннюю
сеть.
Круглые скобки вокруг интерфейса стоят потому, что адрес ему назначается динамически.
Для работы FTP-прокси, добавим якорь:
nat-anchor "ftp-proxy/*"
Во-первых, нам понадобится правило перенаправления для работы ftp-proxy(8), чтобы клиенты из локальной сети могли пользоваться FTP:
rdr-anchor "ftp-proxy/*"
rdr on $int_if proto tcp from any to any port 21 -> 127.0.0.1 port 8021
Заметим, что здесь будет перенаправляться только FTP с
управляющим каналом на порту 21. Если пользователи регулярно
используют другие порты, следует использовать список: from any to any port {21, 221}.
Во-вторых, нам надо перенаправить все входящие соединения на 80-й порт машины COMP3.
rdr on $ext_if proto tcp from any to any port 80 -> $comp3
Для начала определяем политику default deny:
block in
Здесь мы блокировали весь входящий трафик, даже из внутренней сети. Теперь мы будем по очереди описывать правила пропускающие нужный трафик.
Имейте ввиду, что пакетный фильтр может блокировать отдельно входящий трафик и отдельно исходящий. Мы с вами блокировали весь входящий трафик, но если пакет уже вошёл (т.е. он соответствовал разрешающему правилу, которое будет записано ниже), то мы можем его выпустить:
pass out keep state
Нам понадобится якорь для ftp-proxy(8):
anchor "ftp-proxy/*"
Неполохо так же защититься от спуфинга:
antispoof quick for { lo $int_if }
Теперь откроем порты, используемые сервисами, котрые должны быть доступны из Интернет. Для начала, трафик предназначеный самому брандмауэру:
pass in on $ext_if inet proto tcp from any to ($ext_if) \
port $tcp_services flags S/SA keep state
Благодаря указанию портов в макросе $tcp_services добавление нового
сервиса предельно упрощается: достаточно просто
отредактировать определение макроса и перегрузить набор
правил. Чтобы добавить сервисы UDP можно просто добавить
макрос $udp_services аналогичным
образом. При этом понадобится вставить такое же правило с
указанием proto udp.
Далее надо пропустить трафик идущий на машину COMP3, который прошёл трансляцию rdr:
pass in on $ext_if inet proto tcp from any to $comp3 port 80 \
flags S/SA synproxy state
Чтобы немного увеличить безопасность web-сервера мы используем TCP SYN Proxy.
Пропускаем трафик ICMP:
pass in inet proto icmp all icmp-type $icmp_types keep state
Аналогично макросу $tcp_services,
мы можем редактировать макрос $icmp_types, чтобы варьировать типы
пакетов принимаемых брандмауэром. Заметьте, это правило
касается всех интерфейсов.
Теперь мы пропускаем весь трафик из внутренней сети. Мы предполагаем, что пользователи во внутренней сети знают что они делают и это не вызовет проблем. Однако во многих случаях это не так и понадобятся более жёсткие ограничения.
pass in quick on $int_if
Трафик TCP, UDP и ICMP может покидать машину благодаря
правилу «pass out keep
state». Информация о состояниях сохраняется,
таким образом, ответные пакеты тоже будут пропущены.
# макросы
ext_if="fxp0"
int_if="xl0"
tcp_services="{ 22, 113 }"
icmp_types="echoreq"
comp3="192.168.0.3"
# опции
set block-policy return
set loginterface $ext_if
set skip on lo
# нормализация трафика
scrub in
# nat/rdr
nat on $ext_if from !($ext_if) -> ($ext_if:0)
nat-anchor "ftp-proxy/*"
rdr-anchor "ftp-proxy/*"
rdr pass on $int_if proto tcp to port ftp -> 127.0.0.1 port 8021
rdr on $ext_if proto tcp from any to any port 80 -> $comp3
# Фильтрация
block in
pass out keep state
anchor "ftp-proxy/*"
antispoof quick for { lo $int_if }
pass in on $ext_if inet proto tcp from any to ($ext_if) \
port $tcp_services flags S/SA keep state
pass in on $ext_if inet proto tcp from any to $comp3 port 80 \
flags S/SA synproxy state
pass in inet proto icmp all icmp-type $icmp_types keep state
pass quick on $int_if

| |  | |
| C.1. Введение в работу с пакетным фильтром OpenBSD |  | C.3. Управление пакетным фильтром OpenBSD при помощи утилиты pfctl(8) |
HIVE: All information for read only. Please respect copyright! |

