Инструменты прикладного программиста: строковый процессор awk. Описано популярное инструментальное средство среды программиста в UNIX: строковый процессор awk, позволяющий эффективно обрабатывать различную текстовую информацию.
The string processor awk popular in UNIX-like operational systems is described in certain details. This tool allows an application programmer to coup efficiently with processing large amounts of textual information. Intended for application programmers, information systems developers and computer sciences students.
Подобные задания с одной стороны могут быть слишком трудоемки для обычного текстового редактора, так как могут требовать просмотра тысяч строк текста, а с другой стороны -- неунифицируемыми, так как информация не структурирована в том виде, как это имеет место в базах данных или электронных таблицах. Для эффективной работы в этой ''серой'' области давно предложен и с успехом применяется строковый процессор awk.
Это процессор рассматривает входной поток данных
как состоящий из записей,
разделенными специальными символами (RS).
По умолчанию таким символом является символ перехода
на новую строку ('\n').
Запись считается разделенной ( символами FS)
1 на поля
и строковый процессор awk автоматически выделяет эти поля
и дает возможность производить
с ними различные операции.
По сути дела, это единственное предположение,
которое делает awk относительно структуры входных данных.
Задание процесса обработки некоторого файла с помощью программы awk состоит в описании действий, которые нужно произвести с записями и полями. Для этого awk предоставляет в распоряжение программиста развитый язык программирования, напоминающий популярный язык программирования C. Это и не удивительно, так как авторы awk (Альфред В. Ахо ( Alfred V. Aho -- a), Питер Дж. Вайнбергер ( Peter J. Weinberger -- w ) и Брайан У. Кернихан ( Brian W. Kernighan -- k) известны как родоначальники языка C и операционной системы UNIX.
Входной язык процессора awk является в определенном смысле ''упрощенным'' C и не содержит таких типов данных как указатели и структуры. Отсутствуют в нем и другие элементы языка C, такие, напримерa, как команды препроцессора, битовые операции, локализация переменных и пр.
Однако, в отличие от C awk предоставляет удобный операционный синтаксис для строковых операций, автоматическое преобразование строка-число, автоматический лексический разбор входного потока и т.п., что делает его исключительно удобным средством выполнения простых, но трудоемких операций c текстовыми файлами больших размеров. Кроме этого, awk является интерпретирующим языком, что существенно упрощает процесс разработки awk-приложений.
Все это делает awk весьма эффективным и полезным инструментом, умело владеть которым должен каждый грамотный программист.
Программа на awk может содержать определения функций, которые можно считать также имеющими форму образец -- действие со специальным видом образца. Подробнее задание функций описано в разделе [*]
Действие описывается операторами языка awk, которые подробнее рассматриваются далее. Чтобы отделить условие от действия, последнее обычно заключается в фигурные скобки . Ислючение составляет лишь случай пустого действия, которое в этом случае приводит к выводу на печать входной записи.
| /регулярное выражение/ |
| логическое выражение |
| проверка на совпадение |
| диапазон записей |
| заголовок функции |
| BEGIN |
| END |
Понятие регулярного выражения совпадает в основном с регулярными выражениями, признаваемыми grep[1], что неудивительно, так как авторы awk сильно повлияли и на разработку grep.
Простейшим случаем регулярного выражения является строка символов. Программа ( с пустым действием )
/Иванов/
напечатает из текстового файла те строки, которые содержат подстроку
"Иванов" ( в том числе и "Ивановский машиностроительный завод" ).
Образцы-регулярные выражения позволяют более точно описать класс строк, которые необходимо обработать или напечатать.
Помимо обычных символов регулярное выражение может содержать специальные метасимволы, которые дают возможность описывать различные подмножества строк.
Канонический список метасимволов содержит следующие элементы:
^ $ [ ] - + * .(точка) \
Метасимволы имеют следующую сематику:
^ -- соответствует началу строки.
Это позволяет выделять строки
не только по наличию в них тех или иных символов,
но и по их расположению в строке.
Так, например, /^A/ соответствует строкам (записям),
начинающимся на A.
$ -- соответствует концу строки.
Например,
/A$/ отвечает строкам,
заканчивающимся на A.
[ ] -- c помощью этих символов описывают множества единичных символов.
В простейшем случае эти множества описываются перечислением: [AWK]
соответствует множеству из трех букв A, W, K.
Соответственно G[AWK] представляет множество строк
{ GA, GW, GK }.
- -- используется для задания диапазона символов, например,
[a-z] соответствует символам от a до z,
как они расположены в таблице кодов ASCII.
+ -- этот символ обозначает многократное ( не менее одного )
повторение в образце символа, предшествующего +.
* -- также многократное, но возможно также и нулевое повторение
предыдущего символа.
Типичный пример: [1-9][0-9]* -- положительные целые числа.
.(точка) -- обозначает произвольный единичный символ.
Легендарную известность приобрела комбинация .*,
которая обозначает таким образом произвольную комбинацию
символов.
\ -- отменяет специальное значение последующего
символа.
Отмена специального значения \ производится при помощи \\.
Логические выражения строятся с помощью операций,
приведенных в табл. [*].
/^A/ && ! /^AB/
соответствует записям, начинающимся на символ A,
но не имеющим в качестве последующего символа B.
В качестве образца можно указать также и группу строк. Такая группа строк обозначается в поле образца как
образец-1, образец-2
и означает, что соответствующее действие будет выполнятся для строк, которым предшествовала строка, соответствующая образец-1, но предшествующим строке, соответствующей образец-2.
Специальные символы BEGIN, END обозначают начало и конец файла ввода. С их помощью можно выполнить до начала действительной работы awk желаемые действия по настройке awk, а по завершению работы -- выдать какую-либо итоговую информацию.
Тело действия в awk представляет собой программу на языке awk, в котором присутствуют многие из аттрибутов языка программирования: присвоения, выражения, условные операторы, циклы, операторы ввода-вывода, команды работы с файловой системой и пр. Команды awk могут группироваться с помощью тех же самых фигурных скобок {} и образовывать составные операторы.
К восторгу поклонников структурного программирования в awk отсутствует оператор GOTO и метки.
Подробнее команды awk рассмотрены в следующем разделе.
В строке вызова awk можно указать несколько файлов данных, awk будет последовательно их обрабатывать. Имя текущего файла ввода доступно как значение переменной FILENAME.
Эти базовые возможности awk по вводу данных могут быть существенно расширены использованием функции (или команды) getline.
Использованная без аргументов, getline просто читает очередную запись из текущего файла ввода. Это позволяет, например, специальным образом обработать следующую строку, если вы, например, обнаружили во входных данных сообщение типа:
TOP SECRET! NEXT LINE TO BE BURNED BEFORE READING!
После выполнения команды getline awk продолжает нормальный цикл своей деятельности, применяя к этой записи последующие пары образец -- действие.
Команда getline может быть использована для ввода значения строковой переменной:
getline message
Никаких побочных эффектов при этом не происходит, за исключением того, что изменяется счетчик записей NR.
Команда getline может читать из поименованного файла, используя технику перенаправления:
getline < file
Выражение file может быть произвольным строковым выражением, которые интерпретируются как имя файла в данной операционной системе.
Если getline не встретила каких-либо проблем при исполнении, она возвращает значение 1. Если при исполнении обнаружен конец файла, то возвращается 0, если обнаружена ошибка, то возвращается -1. В последнем случае причину ошибки можно найти, проанализировав значение переменной ERRNO.
print a,b,c, ... z
где a, b, c, ..., z это список вывода, который может включать различные строковые и арифметические выражения.
Например, в результате исполнения оператора
print exp(1)
будет напечатано число
2.71828а в результате выполнения оператора
print "Вася" "+" "Маша"
будет напечатана строка
Вася+МашаОбратите внимание, что напечаталась конкатенированная строка, т.е.
"Вася" "+" "Маша"
"Вася+Маша".
Если печать будет производиться оператором
print "Вася","+","Маша"
результат будет обычно выглядеть как
Вася + МашаЗначения списка вывода разделены в этом случае пробелом, которые является значением по умолчанию специальной внутренней переменной OFS. Эта и другие специальные переменные awk будут рассмотрены позднее, а пока заметим, что значение OFS может быть изменено пользователем. Например, если определить
OFS="\n",
то тот же оператор печати выдаст результат
Вася + Маша
Оператор
print $1
выведет на печать содержимое первого, а оператор
print $NF
последнего поля текущей записи.
По умолчанию для вывода чисел awk использует в качестве формата
значение специальной внутренней переменной OFMT,
оычно имеющей значение "%.6g".
Изменив это значение, можно изменить форму вывода чисел, например,
OFMT="%.0f"
будет выводить все числа как целые, округляя их до ближайшего.
Операторы printf, sprintf осуществляют форматированый вывод в духе операторов вывода языка C. Для этих операторов первым элементом списка вывода является строка, содержащая описание форматов вывода последующих элементов списка. Для описания форматов применимы стандартные правила языка C:
| %s | строка символов |
| %d | десятичное целое |
| %f | вещественное число с десятичной точкой |
| %o | восьмеричное число |
| %x | шестнадцатиричное число |
Предопределенные разделители OFS, ORS не влияют на вывод, осуществляемый посредством printf, в частности в конце записи не добавляется автоматически символ перехода на новую строку ( значение ORS по умолчанию ).
Специфика оператора sprintf заключается в том, что вывод происходит не во внешний файл, а возвращается в качестве значения функции sprintf. Соответственно синтаксис sprintf воспроизводит вызов функции в awk:
pi = sprintf("%f10.6", 4*atan(1))
присваивает строковой переменной pi значение " 3.141592".
Вывод операторов print, printf может быть перенаправлен стандартным для UNIX образом. Целью такого перенааправления может служить какой-либо поименованный файл или другая команда операционной системы. В случае файла результат команды print или printf может либо затирать предыдущее содержание файла, либо дописываться к нему. Первое осуществляется командой
print "Вася+Маша" > "message.of.the.day"
а второе -- командой
print "Вася+Маша" » "message.of.the.day"
Следует иметь в виду, что различие между этими вариантами перенаправления существует лишь до открытия файла message.of.the.day и первой операции записи в этот файл. Последующие перенаправления будут давать тот же результат: новые порции выводимой информации будут дописываться к содержанию файла. Если это нежелательно, необходимо в явном виде закрывать файл с помощью оператора close, рассмотренного ниже.
Программа awk допускает также и перенаправление вывода в конвейер. В этом случае опреатор вывода имеет вид
printf A, B, C, ... | CMD
где команда CMD может быть произвольным строковым выражением. Значение этого строкового выражения передается комадному интерпретатору операционной системы для исполнения.
При перенаправлении вывода следует иметь в виду, что некоторые реализации awk накладывают серьезные ограниения на количество одновременно открытых файлов. Поэтому хорошим тоном программирования на awk является немедленное закрытие файлов ввода/вывода, как только в них отпадает необходимость.
Если файлы и конвейеры открываются awk по мере необходимости и остаются открытыми до окончания работы программы, то закрытие файлов осуществляется командами
| close (filename) | закрыть файл filename |
| close (COMMAND) | закрыть конвейер COMMAND. |
print "ERROR" | " cat 1 > & 2"
В разных версиях awk используются разные трюки для работы с
каналами. В частности, в GAWK используются специальные имена,
приведенные в табл. [*].
if (условие) then {
действие-1
}
else {
действие-2
}
Если действие-1 или -2 содержит один единственный оператор,
фигурные скобки не требуются.
К некоторой трудно объяснимой особенности awk относится то, что если действие-1 содержит один операнд, то за ним должна следовать точка с запятой (;).
Цикл do-while имеет вид
do {
тело цикла
} while (условие)
где тело цикла используется по крайней мере один раз и до тех пор
пока условие остается истинным.
Цикл while имеет вид
while (условие) {
тело цикла
}
и проверка условия осуществляется до исполнения тела цикла.
Цикл for имеет две формы в awk: одна -- традиционная:
for(инициализация; условия; завершение){
тело цикла
}
и вторая -- ассоциативная:
for(index in list){
тело цикла
}
где list - ассоциативный массив, подробности работы с которыми будут
рассмотрены ниже.
На содержательном уровне вторая форма оператора for означает
использование тела цикла для каждого элемента ассоциативного
массива list.
Порядок исполнения непредсказуем.
В приведенных конструкциях фигурные скобки {} необязательны если тело цикла представляет собой один оператор.
В отличие от C язык awk содержит две формы операторов досрочного прерывания цикла и досрочного перехода к следующему выполнению тела цикла. Это связано с тем, что сама конструкция awk подразумевает неявный внешний цикл: чтение данных -- обработка.
Для досрочного прекращения этого процесса обработки служит оператор exit. Он по сути дела эквивалентен прерыванию текущих операций обработки и чтению признака конца входного файла (EOF для C-патриотов). Если в awk-программе есть действия, ассоциированные с образом END, они будут выполнены.
Для досрочного прерывания процесса обработки текущей записи (и запуска новой операции чтения - обработки) служит оператор next. Для управления циклами, в явном виде содержащимися в awk-программах, служат операторы break, continue. Оператор break прекращает выполнение цикла, continue запускает новое исполнение тела цикла.
К операторам управления последовательностью операций с некоторой натяжкой можно отнести и return -- оператор возврата из функции, описанной программистом. Оператор
return выражение
позволяет сообщить вызывающей программе в качестве значения функции вычисленные значения выражения.
Например, если перед вами стоит задача разобрать текстовый файл-таблицу, в которой, скажем, в первом столбце находится фамилия работника, получившего вознаграждение, обьем которого находится в седьмом столбце таблицы и трубуется определить суммарное вознаграждение для каждого из работающих, awk решает эту задачу с потрясающей легкостью:
{ payoff[![]() 7 }
7 }
и проблема остается лишь в выводе значений массива payoff по завершению работы программы.
Конечно, для такого понятия массива трудно ввести предварительное декларирование и элементы массивов в awk создаются в момент использования. По исчерпыванию необходимости в этом элементе, от него можно в явном виде избавиться при помощи оператора delete:
delete payoff["Иванов"]
и освободить память для более важных дел. Удалить весь массив payoff можно командой
delete payoff
Определение множества индексов данного массива и обход элементов массива можно произвести с помощью ассоциативного цикла, уже упомянутого выше. Отрывок awk-программы
END {
for(name in payoff)
printf name, payoff[name]
}
как раз и позволит по завершению работы программы
суммирования вознаграждений распечатать список имен работающих и
их суммарное вознаграждение.
Единственным недостатком такого простого решения являетя неопределенный порядок индексов массива payoff, в связи с чем их имена почти наверняка не будут выведены в алфавитном порядке !
Простым выходом из положения будет запуск какой-либо внешней программы сортировки текстовых файлов, которая достаточно разумна для того, чтобы знать о существовании русского алфавита.
Еще одним часто встречающимся способом порождения массивов является использование встроенной функции split. Эта функция может иметь два или три аргумента и используется для разбиение какой-либо строки на отдельные части, заполняющие собой массив.
Например, оператор
n = split("31.12.1999", date, ".")
разобьет строку "31.12.1999" на три части "31", "12", "1999", используя в качестве разделителя символ "." и присвоит массиву date значения:
date[1] = "31", date[2] = "12", date[3] = "1999".Переменной n присвоится, конечно, значение 3.
Если функция split вызывается с двумя аргуменами, подразумевается, что символом-разделителем является значение встроенной переменной awk FS -- по умолчанию пробельный символ.
Таким образом
nn = split($0, tokens)
в явном виде выполнит ту работу, что awk делает по умолчанию:
разделит входную строку ($0) на отдельные элементы и запишет их
в массив tokens.
Количество элементов будет запомнено, как значение переменной nn.
Это полностью эквивалентно явному циклу
for(i = 1; i <= NF; i++) tokens[i] = $i nn = NFно, конечно, намного более эффективно, экономит память и бумагу и, следовательно, сохраняет окружающую среду.
Их основные характеристики приведены в табл. [*].
| Таблица [*]. Встроенные функции языка awk | |
| Численные функции | |
| atan2 | арктангенс |
| cos | косинус |
| exp | экспонента |
| int | целочисленное округление |
| log | натуральный логарифм |
| rand | псевдослучайное число из интервала |
| sin | синус |
| sqrt | квадратный корень |
| srand | инциализация случайного датчика |
| Строковые функции | |
| sub, gsub | выделение подстроки |
| index | поиск мета в строке |
| length | длина строки |
| match | проверка на наличие подстроки |
| split | разбивка строки на элементы |
| substr | выделение подстроки |
| tolower | перевод в нижний регистр |
| toupper | перевод в верхний регистр |
| Функции, определяющие системное время | |
| systime() | возвращает число секунд, прошедших со времени некоторого знаменательного с точки зрения оперционной системы события. На POSIX-стандартных системах это время, прошедшее с полночи 1 января 1979 г. по Гринвичу. |
| strftime( |
возвращает строковое значение временной метки TIME (второй аргумент) в соответствии с форматом FORMAT (первый аргумент). Детали слишком утомительны, чтобы их излагать в таком малом обьеме. |
| Разное | |
| system(s) | строка s интерпретируется как команда операционной системы и исполняется командным интерпретатором. |
Генератор случайных чисел rand() может быть проинициализирован с помощью функции srand(x). По умолчанию в качестве x используется время дня. Если rand() не инициализаруется, то при повторном исполнении awk-программы генерируется та же самая последовательность чисел.
Строковые функции имеют следующий синтаксис и действие:
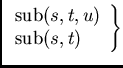
$0.
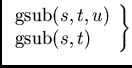
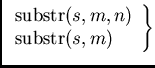

function FunctionName(a, b, ..., z)
{
... тело функции ...
}
Относительно имени функции и имен переменных выполняются обычные соглашения
о допустимых идентификаторах в awk.
Тело функции представляет собой набор awk-команд, применяемых к
списку параметров заголовка функции.
Функция может быть ''реккурсивной'', вызывая самое себя.
Количество аргументов в фактическом вызове функции может отличаться
от количества аргументов в описании.
''Лишние'' переменные получают в качестве значений пустую строку
"".
При вызове функции в awk-программе не должно быть никаких символов
( в том числе и пробельных ) между
именем функции и списком аргументов в скобках.
В awk используется механизм передачи параметров ''по значению'', так что всякие изменения, происходящие с аргументами в функции, не изменяют значений этих переменных вне функции.
Однако, если аргументом функции является массив, значения его элементов могут быть изменены внутри тела функции.
| Каноническое множество | |
| FILENAME | имя файла, обрабатываемого awk в настоящий момент |
| FS | разделитель полей в записи |
| NF | количество полей в текущей записи |
| NR | номер текущуй записи |
| OFS | разделитель полей при выводе |
| ORS | рпзделитель записей при выводе |
| RS | разделитель записей |
$0 |
адресует всю запись целиком |
$n |
адресует |
| gawk | |
| ARGV | массив аргументов командной строки |
| ARGC | количесвто аргументов командной строки |
| CONVFMT | формат внутреннего преобразования ''число'' |
| ENVIRON | массив переменных среды |
| FNR | номер записи в текущем файле |
| IGNORECASE | если эта переменная непуста, то все сравнения awk проводит игнорируя разницу ммежду буквами в верхнем и нижнем регистрах |
| OFMT | формат вывода для чисел |
| RSTART | положение первого совпадения, найденого командой match |
| RLENGTH | длина совпадения, найденого командой match |
| SUBSEP | символ-разделитель для индексов массивов |
Переменные, используемые в программах awk, не требуют предварительного декларирования и их тип определяется контекстом использования. Переменная box может быть проинициализирована строкой "4":
box = "4"затем с ней можно выполнить арифметическое действие
box = box*4и затем строковую операцию ( например, конкатенацию )
box = box " boxes of candies"в результате чего переменная box примет значение "16 boxes of candies".
Преобразование из строкового в числовой тип и обратно происходит прозрачным
для пользователя образом.
Повлиять на это преобразование можно изменив значение встроенной переменной
CONVFMT, которая по умолчанию имеет значение "%.6g".
Результат преобразования числа в строку эквивалентен использованию
функции sprintf c переменной CONVFMT,
определяющей формат преобразования.
При переводе строки в число awk проявляет досточно интеллекта для того, чтобы распознать "100", "1e2", "100fix" как число 100. При переводе в числовую форму строк типа "Вася" возвращается нулевое значение.
Если по каким-либо причинам необходимо форсировано перевести
переменную или выражение из числовой формы в строковую,
рекомендуется
конкатенировать ее с пустой строкой "".
Если необходим перевод из строковой в числовую форму, можно прибавить 0.
Значения переменных в awk определяется не только присвоением, операторами инкремента и декремента, но могут быть определены и в командной строке. Последнее особенно удобно при написании shell-программ, содержащих обращения к awk. Значения переменных опеределяются при этом используя опцию -v. описанную ниже.
Файл данный представляет собой тот файл, к которому применяется awk-программа. Если такой файл отсутствует, по awk-программа применяется к потоку стандартного ввода. Это позволяет применять awk в конвейерах.
Опиции для awk задаются в POSIX-стиле буквой, перед которой располагается знак минус (-). Счастливые пользователи gawk могут использовать ''длиные'' имена для опций в GNU-стиле, перед которыми необходимо разместить два минуса (-). Вызывая gawk, можно вперемешку использовать длиные и короткие формы опций.
Программа awk понимает в основном следующие опции:
 |
Эта опция устанавливает разделитель полей в записи равный FS. |
 |
указывает на то, что awk-программа находится в файле file |
 |
присваивает переменной VAR значение VAL. Присвоение выполняется перед началом работы awk-программы. |
 |
Так же как и f-опция, указывает на то, что awk-программа ( или часть ее ) находится в файле file. Позволяет использовать комбинацию ввода программы через командную строку и из заранее подготовленного файла. |
 |
Сообщает версию awk(gawk). |
| -c | заставляет ''gawk'' работать как ''awk''. |
| - | обозначает конец опций. Далее ''-'' не обозначает начало опции. Эта опция дает возможность работать с файлами, имена которых начинаются на дефис(-). |
{ max = NF > max ? NF : max }
END { print max }
Это программа подсчитывает максимальное число полей в записях.
length($0) < 64
Эта ультракороткая программа печатает все строки короче 64 символов. В частности она может помочь восстановить испорченый uuencode-ированый файл, потерявший в процессе передачи хвостовые пробелы в некоторых строках.
Область действия здесь пуста и поэтому по умолчаниюю производится печать записи.
NF > 0
Эта программа фактически удаляет все пустые строки из файла.
{ if (NF > 0) print }
Эта программа эквивалента предыдущей, но решение о печати записи принимается в области действия, используя условный оператор.
BEGIN { for (i = 1; i <= 10; i++) print int(101 * rand()) }
Эта программа печатает 10 целых случайных чисел из интервала от нуля до 100.
ls -l | awk '{ x += $4 } ; END { print "total bytes: " x }
Эта программа подсчитывает количество байтов в файлах данной директории.
expand FILE | awk '{ x = x < length() ? length() : x }
END { print "maximum line length is " x }''
Определение максимальной длины записи в файле. Предварительная обработка программаой expand превращает символы табуляции в соответствующее число пробелов, чтобы видимая длина строки совпадала с количеством символов.
BEGIN { FS = ":" }
{ print $1 | "sort" }
Эта программа выделяет из файла /etc/passwd с регистрационной информацией имена пользователей и печатает их в алфавитном порядке.
{ nlines++ }
END { print nlines }
Подсчет строк в файле.
END { print NR }
Также подсчет строк в файле,но уже средствами awk.
{ print NR, $0 }
Эта программа нумерут сроки в файле.
Основным местом хранения awk является депозитарий GNU-программного обеспечения http://www.gnu.org, через который можно выйти на многочисленные зеркала. Версию для DOS/WINDOWS можно найти на сайте www.simtel.net и его зеркалах.
27*x = 43
HIVE: All information for read only. Please respect copyright! |

